

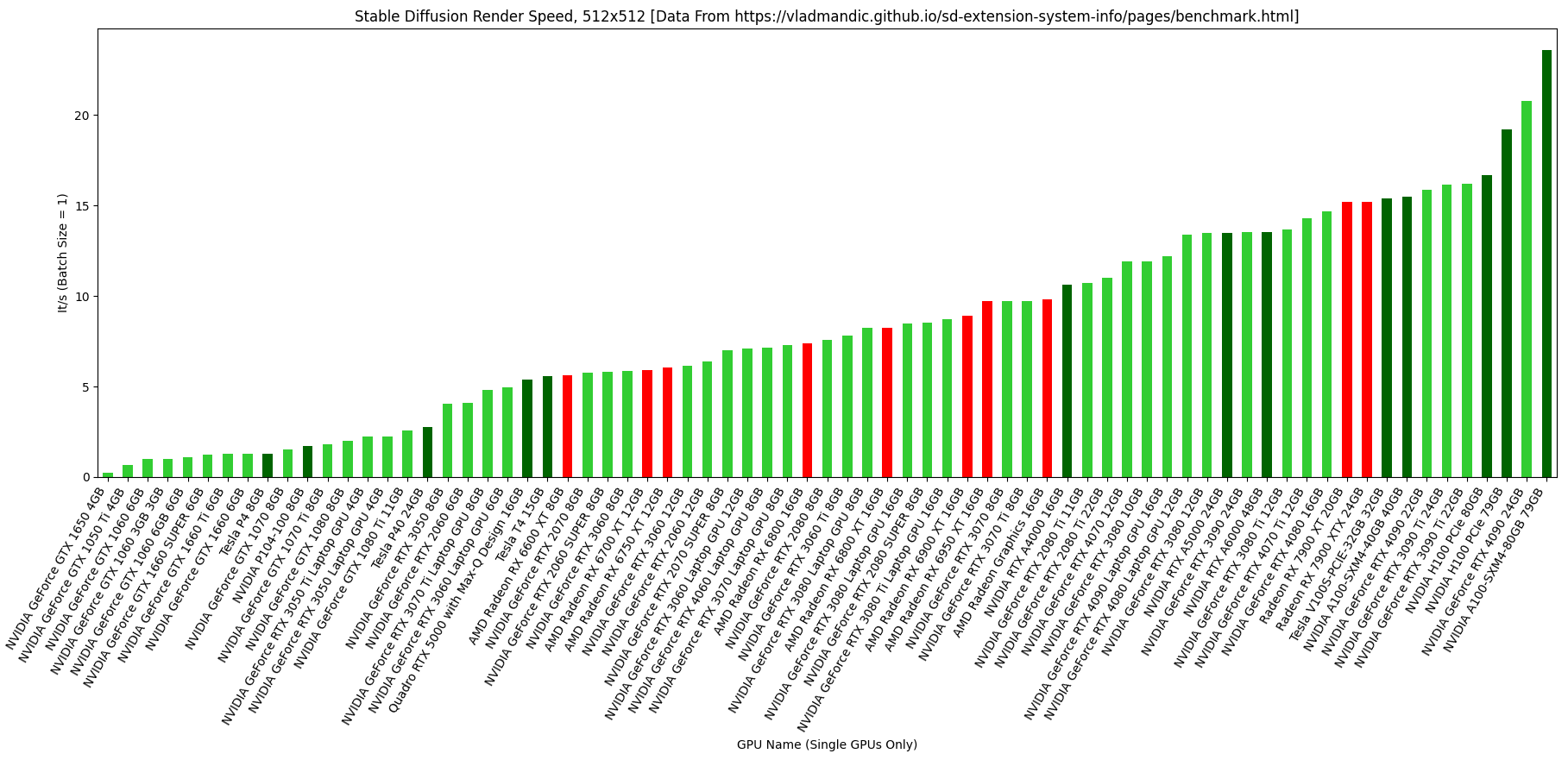
The graphic above summarizes the median 512x512 render speed (batch size 1) for various GPUs. Filtering is for single-GPU systems only, and for GPUs with more than 5 benchmarks only. Data is taken from this database (thank you vladmandic!). Graph is color-coded by manufacturer:
- NVIDIA consumer (lime green)
- NVIDIA workstation (dark green)
- AMD (red)
- Intel (blue), seems there’s not enough data yet
This is an update/prettier visualization from my previous post using today’s data.
Thank you for this very easy digestable graph. Very appreciated.
Happy to help!
Wait a minute, how can a mobile 3060 (12GB one) be faster than the desktop version?
Yeah, the data is definitely not perfect. If I get a chance, I’ll poke around and see if maybe it’s one person throwing off the results. Maybe next time I’ll toss “n=##” or something on top of the bars to show just how many samples exist for each card. I also eventually want to filter by optimization, etc. for the next visualization, though I’m not sure what the best way is to do that except for maybe just doing “best for each card” or something.
So it’s just imperfect sample, I thought mobile 3060 really is faster than the desktop one. Thanks anyway, this graph really helps me choosing GPU.
Yeah, I glanced over it and couldn’t immediately see why the laptop one was benchmarking faster. There were only 7 samples or something for the laptop one, though, so it could just be a fluke. Maybe the laptop folks are using only the best optimization or something. I’ll keep playing with it when I get some spare time.
Awesome graph! It’s a shame the consumer cards have such low amounts of vram. The 4090 kicks ass at compute, but is pretty limited for other AI applications due to the amount of memory.
To be fully fair; that’s kinda what you would expect of consumer cards compared to workstation cards. VRAM is expensive and while these days people are using more VRAM than they used to when playing games there is an upper limit there because devs don’t waste their time creating ultra huge textures that no-one will ever actually see.
Tasks like AI and professional 3D rendering have always benefitted from lots of VRAM, so the cards tailored for them came with more RAM but also very very high markups.
Note: to view full-res, use right-click --> open image in new tab.
It is very helpful to see this graph with laptop options included. Thank you!
-
Is it correct to call this a graph of the empirically measured, parallel computational power of each unit based on the state of software at the time of testing?
-
Also will the total available VRAM only determine the practical maximum resolution size? Does this apply to both image synthesis and upscaling in practice?
I imagine thermal throttling is a potential issue that could alter results.
- Are there any other primary factors involved with choosing a GPU for SD such as the impact of the host bus configuration (PCIE × n)?
The link in the header post includes the methodology used to gather the data, but I don’t think it fully answers your first question. I imagine there are a few important variables and a few ways to get variation in results for otherwise identical hardware (e.g. running odd versions of things or having the wrong/no optimizations selected). I tried to mitigate that by using medians and only taking cards with 5+ samples, but it’s certainly not perfect. At least things seem to trend as you’d expect.
I’m really glad vladmandic made the extension & data available. It was super tough to find a graph like this that was remotely up-to-date. Maybe I’ll try filtering by some other things in the near future, like optimization method, benchmark age (e.g. eliminating stuff prior to 2023), or VRAM amount.
For your last question, I’m not sure the host bus configuration is recorded – you can see the entirety of what’s in a benchmark dataset by scrolling through the database, and I don’t see it. I suspect PCIE config does matter for a card on a given system, but that its impact is likely smaller than the choice of GPU itself. I’d definitely be curious to see how it breaks down, though, as my MoBo doesn’t support PCIE 4.0, for example.
For your last question, I’m not sure the host bus configuration is recorded – you can see the entirety of what’s in a benchmark dataset by scrolling through the database, and I don’t see it. I suspect PCIE config does matter for a card on a given system, but that its impact is likely smaller than the choice of GPU itself. I’d definitely be curious to see how it breaks down, though, as my MoBo doesn’t support PCIE 4.0, for example.
I too would be interested to see how that breaks down. I’m sure that interface does have an impact on raw speed, but actually seeing what that looks like in terms of real life impact would be great to know. While I doubt there are many people who are specifically interested in running SD using an external GPU via Thunderbolt or whatever, for the sake of human knowledge it’d be great to know whether that is actually a viable approach.
I’ve always loved that external GPUs exist, even though I’ve never been in a situation where they were a realistic choice for me.
Hey thanks again for sharing this. I spent all afternoon playing with the raw data. I just finished doing a spreadsheet of all of the ~700 entries for Linux hardware excluding stuff like LSFW. I spent way too long trying to figure out what the hash and HIPS numbers corelate to and trying to decipher which GPU’s are likely from laptops. Maybe I’ll get that list looking a bit better and post it on paste bin tomorrow. I didn’t expect to see so many AMD cards on that list, or just how many high end cards are used. The most reassuring aspect for me to see are all of the generic kernels being used with Linux. There were several custom kernels, but most were the typical versions shipped with a LTS distro.
I’m a Windows caveman over here, but you should definitely post your Linux findings on here when you’re ready! Also, if you have suggestions for how to slice this, I’d be happy to take a stab at it. This was a quick thing I did while ogling a GPU upgrade, so it’s not my best work haha.
I made a post on c/Linux about this today (https://lemmy.world/post/1112621) and added a basic summary of the Linux specific data. I’m still trying to figure everything out myself. I had to brute force the github data for a few hours in Libra Calc (FOSS excel) to distil it down to something I could understand, but I still have a ton of questions.
Ultimately I’ve just been trying to figure out what the most powerful laptop graphics cards are and which ones have the most RAM. So far, it looks like the RTX3080Ti came in some laptops and has 16GB of RAM. Distilling out the full spectrum of laptop options is hard. Anyone really into Linux likely also wants to avoid nvidia as much as possible so navigating exactly where AMD is at right now is a big deal. (The AMD stuff is open source with good support from AMD while nvidia is just a terrible company that does not give a rats ass about the end user of their products.) I do not care if SD on AMD takes twice as long to do the same task as nvidia, so long as it can still do the same task. Open source means full ownership to me and that is more important in the long term.
-
Is anyone running SD on AMD GPUs in Windows? The AMD benches seem to all be from Linux because of ROCm, presumably, but I’d be curious to know how much performance loss comes from using DirectML on, say, a 7900XT in Windows.


{kind=link}