

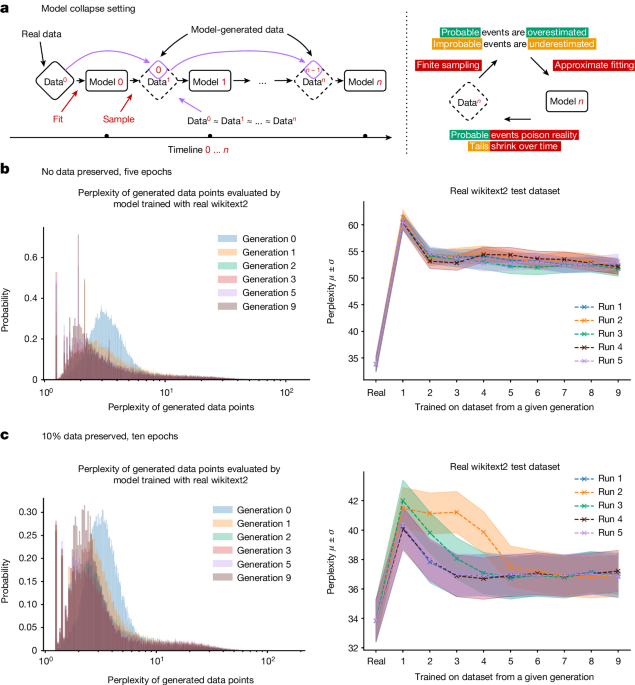
It is now clear that generative artificial intelligence (AI) such as large language models (LLMs) is here to stay and will substantially change the ecosystem of online text and images. Here we consider what may happen to GPT-{n} once LLMs contribute much of the text found online. We find that indiscriminate use of model-generated content in training causes irreversible defects in the resulting models, in which tails of the original content distribution disappear. We refer to this effect as ‘model collapse’ and show that it can occur in LLMs as well as in variational autoencoders (VAEs) and Gaussian mixture models (GMMs). We build theoretical intuition behind the phenomenon and portray its ubiquity among all learned generative models. We demonstrate that it must be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of LLM-generated content in data crawled from the Internet.
Honestly, that’s pretty much what I expected. It’s just an incestuous mash up of pre-existing data. The only way I could see it working is by expanding specific key terms to help an AI identify what something is or isn’t. For example, I have a local instance generate Van Gogh paintings that he never made because I love his style. Unfortunately, there’s a bunch of quirks that go along with that. For instance: Lots of pictures of bearded men, flowers, and photos of paintings. Selecting specific images to train the model on “Van Gogh” might make sense because of the quality of the initial training data. Doing it recursively and automatically? That’s bad mojo.