
BAIR Shares LMD - The Fusion of GPT-4 and Stable Diffusion
By Long Lian, Boyi Li, Adam Yala, Trevor Darrell
Quick Summary
How does it work?: Text Prompt → Large Language Model (LLM) → Intermediate Representation → Stable Diffusion → Final Image.
The Problem: Existing diffusion models excel at text-to-image synthesis but often fail to accurately capture spatial relationships, negations, numeracy, and attribute assignments in the prompt.
Our Solution: Introducing LLM-grounded Diffusion (LMD), a method that significantly improves prompt understanding in these challenging scenarios.

Figure 1: LMD enhances prompt understanding in text-to-image models.
The Nitty-Gritty
Our Approach
We sidestep the high cost and time investment of training new models by using pretrained Large Language Models (LLMs) and diffusion models in a unique two-step process.
- LLM as Layout Generator: An LLM generates a scene layout with bounding boxes and object descriptions based on the prompt.
- Diffusion Model Controller: This takes the LLM output and creates images conditioned on the layout.
Both stages use frozen pretrained models, minimizing training costs.
Read the full paper on arXiv
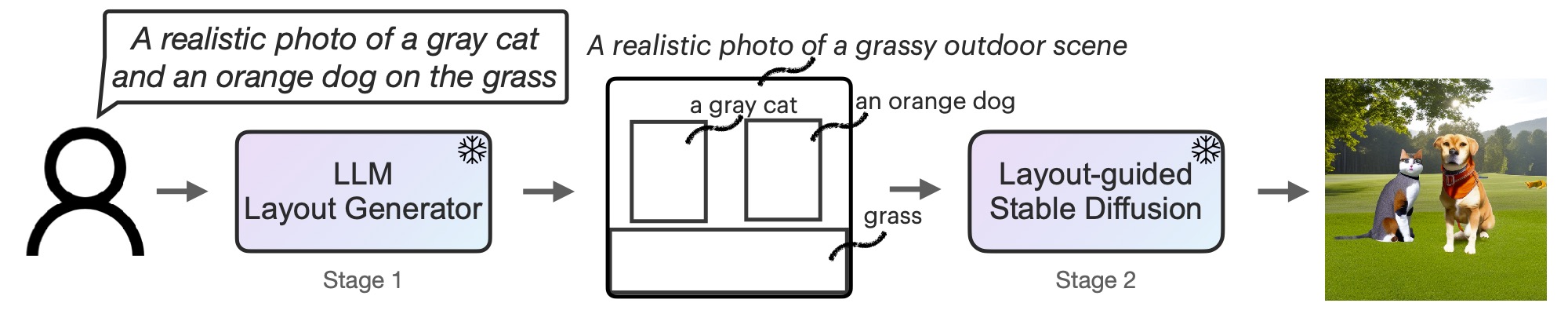
Figure 2: The two-stage process of LMD.
Additional Features
- Dialog-Based Scene Specification: Enables interactive prompt modifications.
- Language Support: Capable of processing prompts in languages that aren’t natively supported by the underlying diffusion model.

Figure 3: LMD’s multi-language and dialog-based capabilities.
Why Does This Matter?
We demonstrate LMD’s superiority over existing diffusion models, particularly in generating images that accurately match complex text prompts involving language and spatial reasoning.
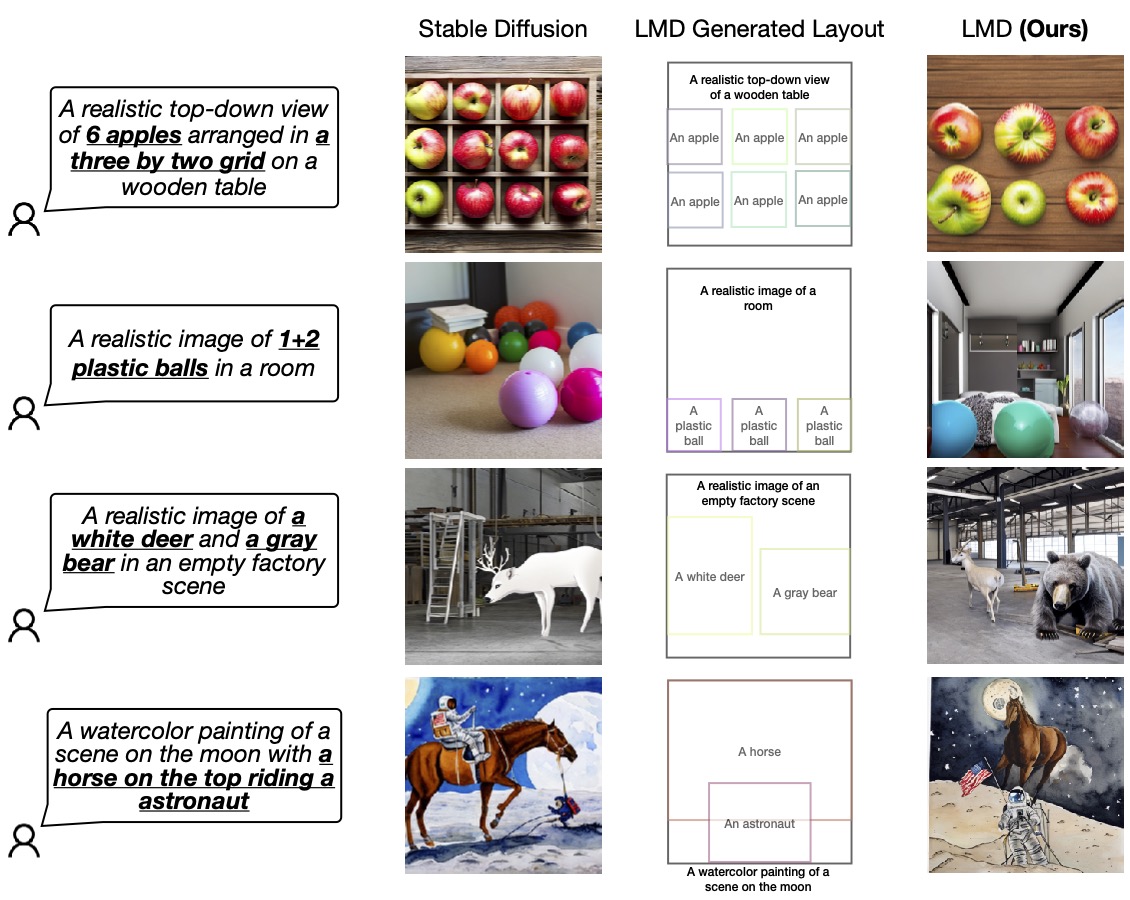
Figure 4: LMD vs Base Diffusion Model.
Further Reading and Citation
For an in-depth understanding, visit the website and read the full paper.
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models},
author={Lian, Long and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
year={2023}
}
Neat! I wonder if this could be improved even further if they used GPT4’s multimodal capabilities, once they are released.