
DeepMind - Building Interactive Agents in Video Game Worlds
Most artificial intelligence (AI) researchers now believe that writing computer code which can capture the nuances of situated interactions is impossible. Alternatively, modern machine learning (ML) researchers have focused on learning about these types of interactions from data.
To explore these learning-based approaches and quickly build agents that can make sense of human instructions and safely perform actions in open-ended conditions, we created a research framework within a video game environment.
Today, we’re publishing a paper and collection of videos, showing our early steps in building video game AIs that can understand fuzzy human concepts – and therefore, can begin to interact with people on their own terms.

Learning in “the playhouse”
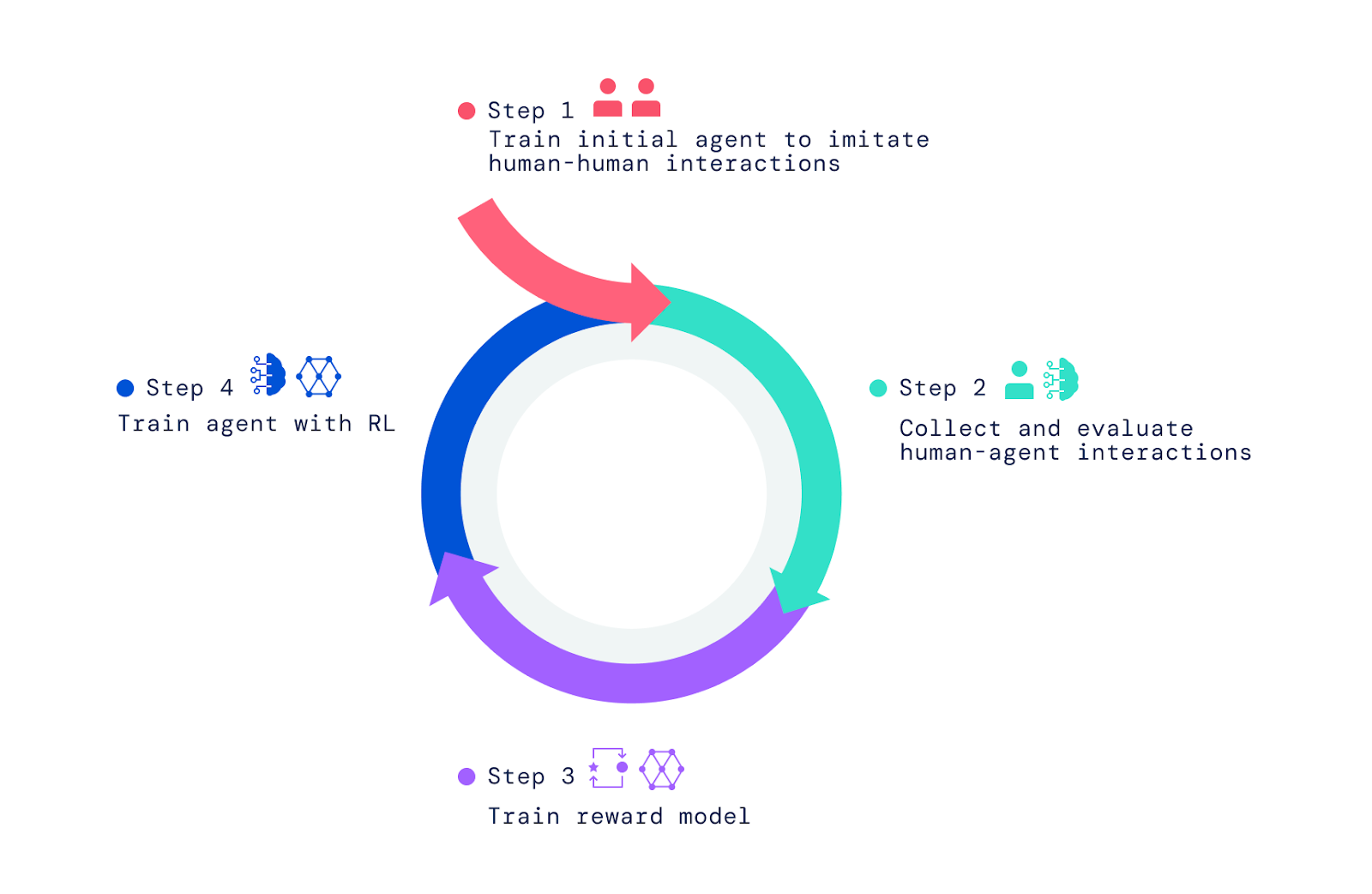
Our framework begins with people interacting with other people in the video game world. Using imitation learning, we imbued agents with a broad but unrefined set of behaviours. This “behaviour prior” is crucial for enabling interactions that can be judged by humans. Without this initial imitation phase, agents are entirely random and virtually impossible to interact with. Further human judgement of the agent’s behaviour and optimisation of these judgements by reinforcement learning (RL) produces better agents, which can then be improved again.
We built agents by (1) imitating human-human interactions, and then improving agents though a cycle of (2) human-agent interaction and human feedback, (3) reward model training, and (4) reinforcement learning. First we built a simple video game world based on the concept of a child’s “playhouse.” This environment provided a safe setting for humans and agents to interact and made it easy to rapidly collect large volumes of these interaction data. The house featured a variety of rooms, furniture, and objects configured in new arrangements for each interaction. We also created an interface for interaction.
Both the human and agent have an avatar in the game that enables them to move within – and manipulate – the environment. They can also chat with each other in real-time and collaborate on activities, such as carrying objects and handing them to each other, building a tower of blocks, or cleaning a room together. Human participants set the contexts for the interactions by navigating through the world, setting goals, and asking questions for agents. In total, the project collected more than 25 years of real-time interactions between agents and hundreds of (human) participants.
Observing behaviours that emerge The agents we trained are capable of a huge range of tasks, some of which were not anticipated by the researchers who built them. For instance, we discovered that these agents can build rows of objects using two alternating colours or retrieve an object from a house that’s similar to another object the user is holding.
These surprises emerge because language permits a nearly endless set of tasks and questions via the composition of simple meanings. Also, as researchers, we do not specify the details of agent behaviour. Instead, the hundreds of humans who engage in interactions came up with tasks and questions during the course of these interactions.