

They are referencing this paper: LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset from September 30.
The paper itself provides some insight on how people use LLMs and the distribution of the different use-cases.
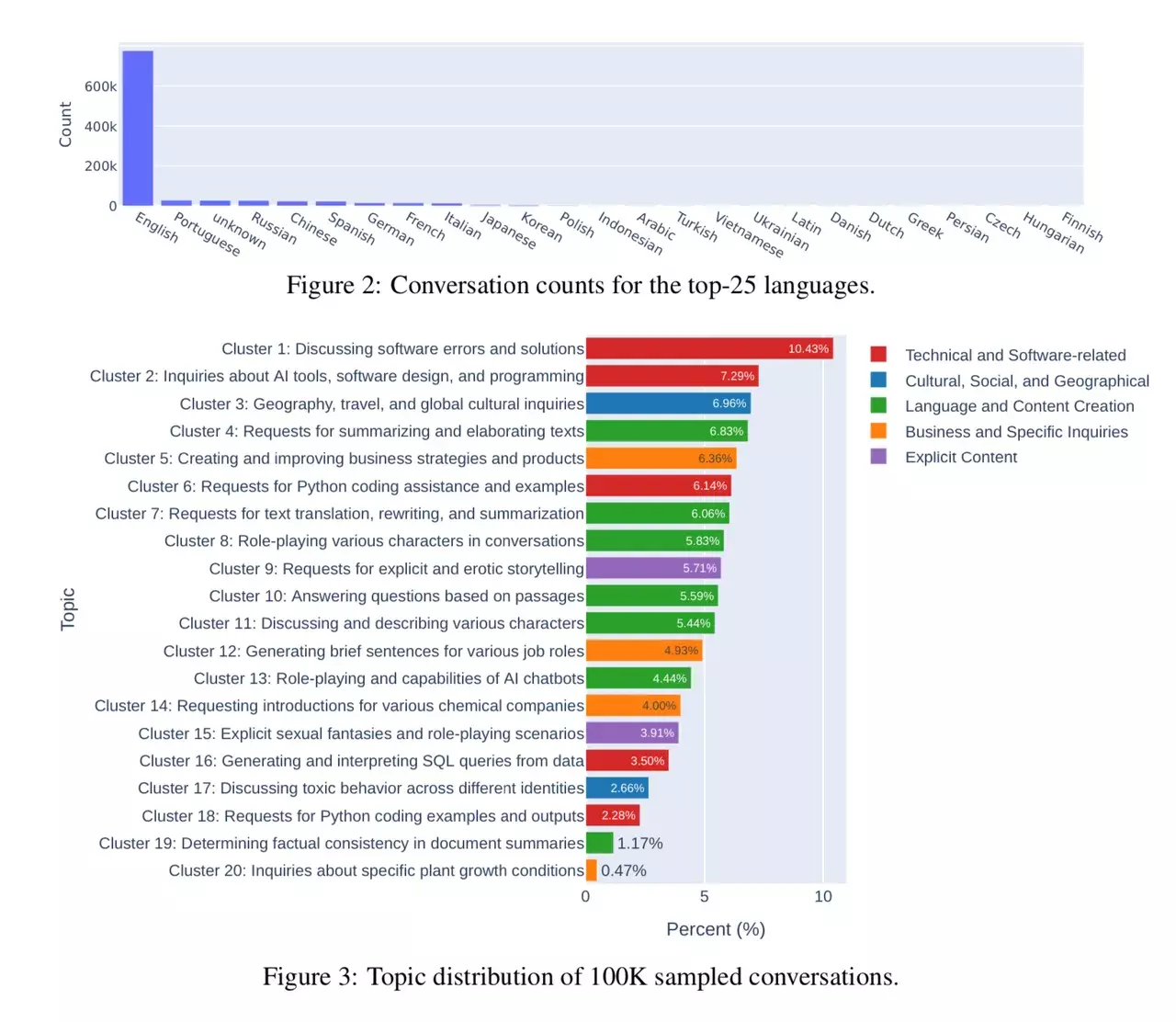
The researchers had a look at conversations with 25 LLMs. Data is collected from 210K unique IP addresses in the wild on their Vicuna demo and Chatbot Arena website.
Will it lead them astray? That is simply not possible. LLMs don’t learn from input. They are trained on a dataset and then can not “learn” new things. That would require a new training, resulting in a new LLM.
Of course, the creator of the LLM could adapt to this and include more of different such things in the training data. But that is a very deliberate action.
I agree, that question at the end is a bit too clickbaity. It is of concern for the next iterations of LLMs if the ‘wrong’ kind of usage creeps into their datasets. But that’s what AI safety is for and you better curate your datasets and align the models for your intended use-case. AFAIK all the professional LLMs have some research done on their biases. And that’s also part of legislative attempts like what the EU is currently debating.
As I use LLMs for that 10% use-case I like them to know about those concepts. I believe stable diffusion is a bit ahead on this, didn’t they strip nude pictures from the dataset at some point and that’s why lots of people still use SD1.5 as the basis for their projects?
Stable Diffusion 2 base model is trained using what we would today refer to as a “censored” dataset. Stable Diffusion 1 dataset included NSFW images, the base model doesn’t seem particularly biased towards or away from them and can be further trained in either direction as it has the foundational understanding of what those things are.
There is already a ton of NSFW text stuff online, so I don’t think anything changes.