
1·
15 days agoSimple and cool.
Florence 2 image captioning sounds interesting to use.
Do people know of any other image-to-text models (apart from CLIP) ?
Simple and cool.
Florence 2 image captioning sounds interesting to use.
Do people know of any other image-to-text models (apart from CLIP) ?
Wow , yeah I found a demo here: https://huggingface.co/spaces/Qwen/Qwen2.5
A whole host of LLM models seems to be released. Thanks for the tip!
I’ll see if I can turn them into something useful 👍
That’s good to know. I’ll try them out. Thanks.
Hmm. I mean the FLUX model looks good
, so there must maybe be some magic with the T5 ?
I have no clue, so any insights are welcome.
T5 Huggingface: https://huggingface.co/docs/transformers/model_doc/t5
T5 paper : https://arxiv.org/pdf/1910.10683
Any suggestions on what LLM i ought to use instead of T5?

Good find! Fixed. It was well appreciated.
Fair enough
I get it. I hope you don’t interpret this as arguing against results etc.
What I want to say is ,
If implemented correctly , same seed does give the same result for output for a given prompt.
If there is variation , then something in the pipeline must be approximating things.
This may be good (for performance) , or it may be bad.
You are 100% correct in highlighting this issue to the dev.
Though its not a legal document , or a science paper.
Just a guide to explain seeds to newbies.
Omitting non-essential information , for the sake of making the concept clearer , can be good too.
Perchance dev is correct here Allo ;
the same seed will generate the exact same picture.
If you see variety , it will be due to factors outside the SD model. That stuff happens.
But it’s good that you fact check stuff.
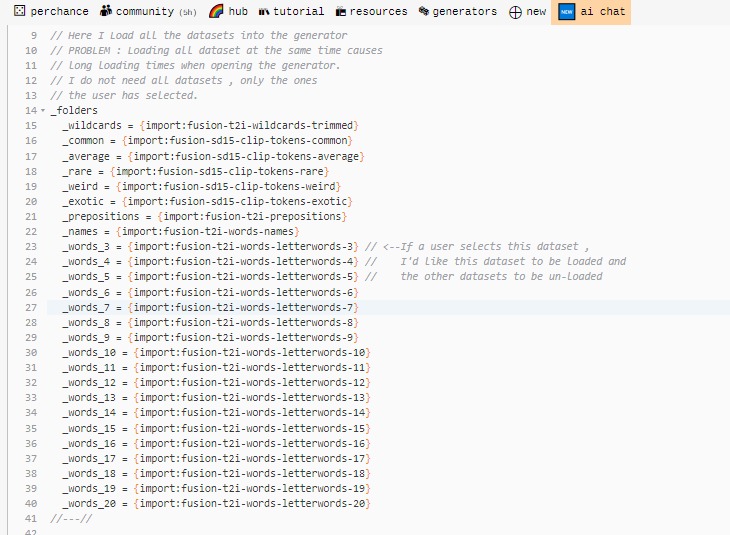
Do you know where I can find documemtation on the perchance API?
Specifically createPerchanceTree ?
I need to know which functions there are , and what inputs/outputs they take.
Thanks! I appreciate the support. Helps a lot to know where to start looking ( ; v ;)b!
New stuff


Paper: https://arxiv.org/abs/2303.03032
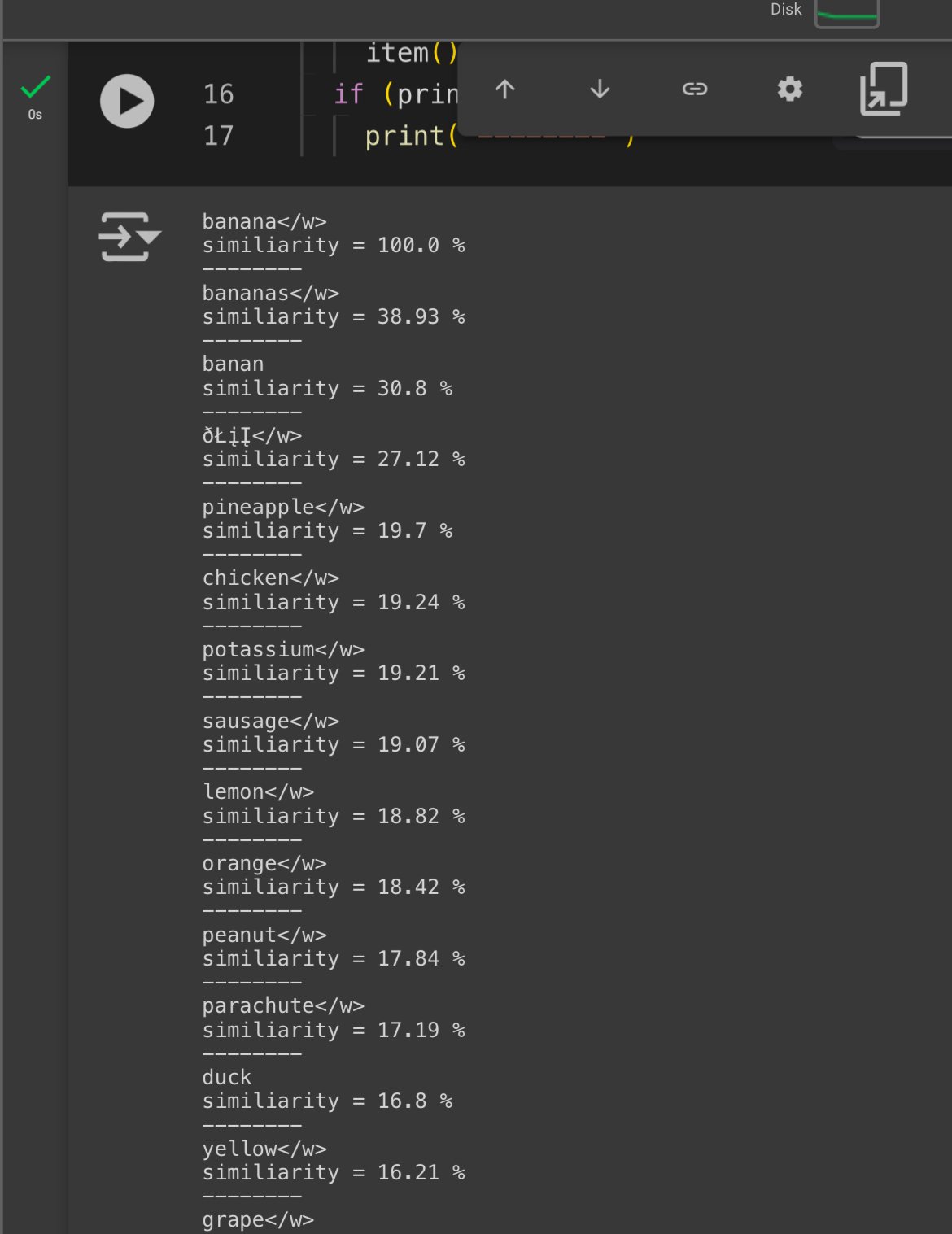
Takes only a few seconds to calculate.
Most similiar suffix tokens : "vfx "
most similiar prefix tokens : “imperi-”
I count casualty_rate = number_shot / (number_shot + number_subdued)
Which in this case is 22/64 = 34% casualty rate for civilians
and 98/131 = 75% casualty rate for police
So its 64-131 between work done by bystanders vs. work done by police?
And casualty rate is actually lower for bystanders doing the work (with their guns) than the police?
I can’t speculate.
If you feel up for the task I’d suggest running prompts that use Euler a at 20 steps for a given seed using that model and see if results match images on the perchance site.
If they do , then we know the furry model = Pony diffusion
(Though IIRC the furry model on perchance existed before Pony Diffusion. )
Aha. So what you wanted to say was that “Starlight” and/or “Glimmer” are triggerwords for the furry model. Gotcha!
Those are both the furry model tho?
From what I know it is possible to bypass the keyword trigger by writing something like _anime or _1girl

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I appreciate you took the time to write a sincere question.
Kinda rude for people to downvote you.