That’s an error I had not seen before, but I also just encountered with this specific post. I will investigate, thanks.

Salamander
- 338 Posts
- 439 Comments
Joined 3 years ago
Cake day: December 19th, 2021
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
This error is a rate limit from the object storage provider. I did not know of this limit when I chose them, and I still have not found a way to change the limit. I will send them an e-mail. If the limit can’t be increased, one option is to pick another object storage provider, but the migration takes days.


 13·5 days ago
13·5 days agoCheck in your settings whether you have disabled the visibility of bot responses. This can happen if bots replied to you and your settings are set to not see them.


 4·6 days ago
4·6 days agoAh - does the exit node participate at all when accessing a .onion? Or is it skipped altogether?
And the HTTP header thing is very cool, I did not know about that!
I have added the header to the site and it works!

I just added the following line to the location / {} block in the https server section:
add_header Onion-Location http://mandermybrewn3sll4kptj2ubeyuiujz6felbaanzj3ympcrlykfs2id.onion/$request_uri;
In the context of tor, a domain block would apply - for example - if the exit node’s ISP blocks the domain. But if the local network implements domain blocks, this would not affect the tor browser - is this correct? Or is it also possible to block domains locally even for tor browser users?








Thank you for being alert! I have banned them instance-wide now.
 1·24 days ago
1·24 days agoInderdaad, ik ben ook voor die marketing gevallen.
Denk je dat mmWave binnenkort beschikbaar zal zijn? Op dit moment heb ik een sub-6 GHz 5G-router voor internet thuis. Ik ben benieuwd hoe een mmWave-router zou presteren als er een zendmast in de buurt is.
Appointed! Sorry about the hassle. I also learned about these federated community bugs just now.

 2·29 days ago
2·29 days agoThis work using high-throughput combinatorial chemistry to find molecules to stop/revert aging is amazing. I have been looking it in the past few days. The authors screened 653,000 different compounds, I am very curious about how expensive this screening was.
I was not aware of DePinho but I am familiar with Schultz’s work. I thought that would get a Nobel prize for his work on non-canonical amino acids, but he hasn’t yet. I am now placing my bets, Ronald DePinho and Peter G. Schultz will win a Nobel prize.
I tried it out and it works well with only SDR++. I have edited my post to correct this, thanks!

Ah!! I over complicated things then. It wouldn’t work for me at first and I eventually converged to this apparently sub-optimal configuration. Tomorrow I will check and edit the post accordingly, thank you!
Publishing in a more prestigious journal usually means that your work will be read by a greater number of people. The journal that a paper is published on carries weight on the CV, and it is a relevant parameter for committees reviewing a grant applicant or when evaluating an academic job applicant.
Someone who is able to fund their own research can get away with publishing to a forum, or to some of the Arxivs without submitting to a journal. But an academic that relies on grants and benefits from collaborations is much more likely to succeed in academia if they publish in academic journals. It is not necessarily that academics want to rely on publishers, but it is often a case of either you accept and adapt to the system or you don’t thrive in it.
It would be great to find an alternative that cuts the middle man altogether. It is not a simple matter to get researchers to contribute their high-quality work to a zero-prestige experimental system, nor is it be easy to establish a robust community-driven peer-review system that provides a filtering capacity similar to that of prestigious journals. I do hope some alternative system manages to get traction in the coming years.
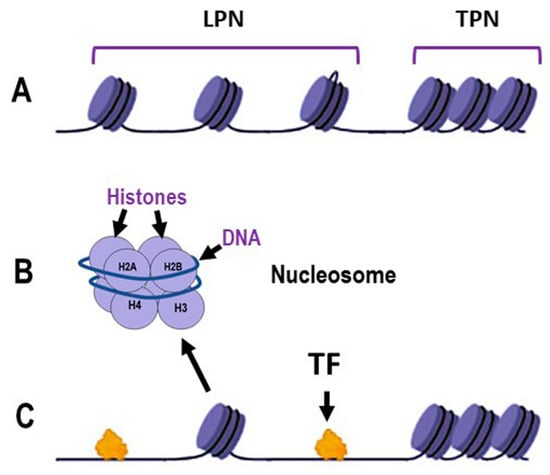
The structure is shown in the full text:

 1·1 month ago
1·1 month agoI have been very succesful with indoor peppers. With tomatoes I had too much plant and a few cherry tomatoes (from a supermarket cherry tomato’s seed)
That’s really cool, I will use it
There is a bit of humor and a bit of truth. I don’t have a garden and so when I was looking into whether it was possible to grow a pumpkin in a pot, most of what I found stated that the pumpkins need a lot of ground to have a strong and healthy root system, and a lot of sun, and so it is not recommended to grow them indoors. I thought that the plant would begin to grow but at some point the pot would not be able to sustain the root system and the plant would die. This has happened to me with many trees that I try to grow indoors - most recently my tamarind trees. They look perfectly healthy and then drop dead. Well, I am not certain of why the trees die but I suspect their roots rot.
But the humor is that I still don’t think it is a good idea to grow this plant indoors. It has taken over a lot of space! My original plan was to prune it and keep it small, but I noticed that even the farthest leaves are able to pull moisture from the pot with no problem, and so I am letting the plant grow to see what happens.
The sensors are from AZDelivery, these ones. They are connected to an arduino nano which reads the capacitance values and sends them over to a raspberry pi 5. The raspberry pi 5 is connected to a few other sensors (CO2, particle counter, air humidity and temperature all from Sensirion), and there is a 7-inch raspberry pi display that the pi writes images to. I was making a home air quality station but I decided to place everything around the pumpkin instead for now, to see if I could get something interesting out of that. But, so far most of them have not been practically useful.
 5·1 month ago
5·1 month agoI did not know of the term “open washing” before reading this article. Unfortunately it does seem like the pending EU legislation on AI has created a strong incentive for companies to do their best to dilute the term and benefit from the regulations.
There are some paragraphs in the article that illustrate the point nicely:
In 2024, the AI landscape will be shaken up by the EU’s AI Act, the world’s first comprehensive AI law, with a projected impact on science and society comparable to GDPR. Fostering open source driven innovation is one of the aims of this legislation. This means it will be putting legal weight on the term “open source”, creating only stronger incentives for lobbying operations driven by corporate interests to water down its definition.
[…] Under the latest version of the Act, providers of AI models “under a free and open licence” are exempted from the requirement to “draw up and keep up-to-date the technical documentation of the model, including its training and testing process and the results of its evaluation, which shall contain, at a minimum, the elements set out in Annex IXa” (Article 52c:1a). Instead, they would face a much vaguer requirement to “draw up and make publicly available a sufficiently detailed summary about the content used for training of the general-purpose AI model according to a template provided by the AI Office” (Article 52c:1d).
If this exemption or one like it stays in place, it will have two important effects: (i) attaining open source status becomes highly attractive to any generative AI provider, as it provides a way to escape some of the most onerous requirements of technical documentation and the attendant scientific and legal scrutiny; (ii) an as-yet unspecified template (and the AI Office managing it) will become the focus of intense lobbying efforts from multiple stakeholders (e.g., [12]). Figuring out what constitutes a “sufficiently detailed summary” will literally become a million dollar question.
Thank you for pointing out Grayjay, I had not heard of it. I will look into it.
Moderates







- New Communities@mander.xyz






- Photosynthesis@mander.xyz

- Botany@mander.xyz
- Plants@mander.xyz

- Semiconductors@mander.xyz
- Radioactive@mander.xyz

- Nuclear@mander.xyz
- Animal behavior@mander.xyz

- Invertebrates@mander.xyz
- Biophysics@mander.xyz
- Self sufficiency@mander.xyz

- Molecular Motors@mander.xyz
- Nudibranchs@mander.xyz
- Sleep@mander.xyz

- test@mander.xyz
- Exercise and Sports Science@mander.xyz
- Bioelectronics@mander.xyz


- Timelapse@mander.xyz
- Photonics@mander.xyz
- Neuroscience@mander.xyz
I adore the odor of those flowers 😌