

7·
1 month agoJoku oli jossain esittänyt kysymyksen, että oliko tämä poliisin toiminta salakatselua?
Joku oli jossain esittänyt kysymyksen, että oliko tämä poliisin toiminta salakatselua?

I’m not advocating for breaking any rules, but many people dont know that you can hide your wifi routers SSID. even fewer people know how to track these networks.
I’ve been toying with Perplexica over the last few weeks occasionally, it feels really restrictive.
I’ve had to modify the internal prompts to make it generate better search terms with my SearxNG (And depending on what LLM model you use, you need to fine tune this…) and having to rebuild the container image to do this has just been annoying. Overall, I’ve had experience with self-hosted LLM web searches on Open-webui, but perplexica is a fun project to try out nevertheless.
No tämähän selittää että miksi tätä ei löydy yhdestäkään hakukoneesta.
Taidankin laittaa sähköpostia tästä eteenpäin, voisi helpottaa ihmisiä löytämään oikean osoitteen.
On varmaa kyllä, tuolla wordpress-asennus näyttää olevan jossa on materiaalia ainakin vuodesta 2020 alkaen, mahdollisesti vielä aiempaakin sisältöä.
Kyseinen domaini on myös Hurstin Avun yhdistyksen omistuksessa, sekä Suomen yritysrekistereissä tätä käytetään Hurstin Avun sähköpostilaatikkona. (YTJ lähde)
whois hurstinapu.fi
domain…: hurstinapu.fi status…: Registered created…: 17.10.2013 01:52:35 expires…: 17.10.2025 01:52:34 available…: 17.11.2025 01:52:34 modified…: 17.9.2020 09:07:17 RegistryLock…: no
Nameservers
nserver…: ns1.euronic.fi [185.55.84.18] [OK] nserver…: ns2.euronic.fi [185.55.84.19] [OK] nserver…: ns3.euronic.fi [92.243.21.222] [OK]
DNSSEC
dnssec…: no
Holder
name…: Veikko ja Lahja Hurstin Laupeudentyö ry register number…: 1980574-9 address…: Ounasvaarankuja 1 postal…: 00970 city…: Helsinki country…: Finland phone…: holder email…:
Registrar
registrar…: Domainkeskus Oy www…: www.domainkeskus.com
Last update of WHOIS database: 20.8.2024 13:16:07 (EET) <<<
This is a bit off-topic, but did you try to increase the JVM limits inside Yacy’s administration panel?
This setting located in /Performance_p.html-page for example gives the java runtime more memory. Same page also has other settings related to ram, such as setting how much memory Yacy must leave unused for the system. (These settings exist so people who run Yacy on their personal machines can have guaranteed resources for more important stuff)
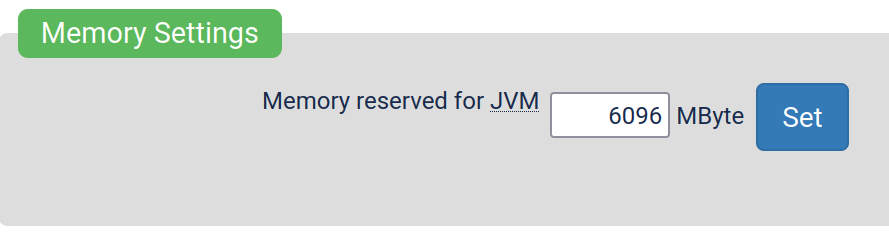
Other things that would reduce memory usage is to limit the concurrency of the crawler for example. There’s quite a lot of tunable settings that can affect memory usage. Would recommend trying to hit up one of the Yacy forums is also good place to ask questions. The Matrix channel (and IRC) are a bit dead, but there are couple of people including myself there!
Also, theres new docs written by the community, they might help as well! https://yacy.net/docs/ https://yacy.net/operation/performance/
Yes, I mentioned Kagi because of the Teclis search index is hosted by them.
However, most of the search results in Kagi are aggregated from dedicated search engines. (such as, but not limited to: Yandex, Brave, Google, Bing, etc.)
Teclis - Includes search results from Marginalia, free to use at the moment. This search index has been in the past closed down due to abuse.
Kagi, whose creation Teclis is, is a paid search engine (metasearch engine to be more precise) also incorporates these search results in their normal searches. I warmly recommend giving Kagi a try, it’s great, I’ve been enjoying it a lot.
–
Other options I can recommend; You could always try to host your own search engine if you have list of small-web sites in mind or don’t mind spending some effort collecting such list. I personally host Yacy [github link] (and Searxng to interface with yacy and several other self-hosted indexes/search engines such as kiwix wiki’s.). Indexing and crawling your own search results surprisingly is not resource heavy at all, and can be run on your personal machine in the background.
Have you tried Grayjay?

Hey! I noticed this anime was being made in recent Paolo from Tokyo’s video of daily life of anime director!
OMEGATRON is that you?

Yes, correct.
I apologize if someone misunderstood my reply, Plex was the bad actor here.
Still with Hetzner yeah. Haven’t had to deal with Hetzner customer support in the recent years at all, but they have been great in the past.
Plex is a great example here. I’ve been Hetzner customer for many many years, and bought a lifetime license to Plex. Only to receive few months later a notification from Plex that I am no longer allowed to self-host Plex for myself(and only myself) at Hetzner and that they will block all access to my self-hosted Plex instance. I tried to ask for leniency or a refund, but that was wasted effort as well.
In short, I was caught on a crossfire when for-profit company tried to please hollywood by attempting to reduce piracy, so they could get new VC funding.
…
I am now a happy Jellyfin user and warmly recommend all Plex users to try it, the Jellyfin community is awesome!
(Use your favourite search engine to look up “Hetzner Plex ban” for more details)
I wish I knew not to trust closed source self-hosted applications, such as Plex. Would have saved a lot of time and money.
Kagi is a metasearch-engine (apart from their homebrew small-web index, known as Teclis), so the reddit lenses will continue to function long as one of the search engines it’s querying is paying reddit.
Ihmettelin myös kun Pöllölaakso purettiin, missään ei ole edes uutisoitu tästä. Rakennuskompleksi on kuitenkin sen verran tunnettu että kaikki on nähnyt videoita/sarjoja/elokuvia/uutislähetyksiä yms tästä rakennuksesta tai sen lähiympäristöstä…
Tuleepahan varmasti kauniita kerrostaloja tilalle “:)”.

“See you next year at the same time?” -Hacker.
Tulin ilmoittamaan että omalla osalla meni tällä copy-pastella läpi!
Kiitos!



Tässä tapauksessa joo.
Mutta mitäs sitten kun joku antaa avaimet valtakuntaan poliisille, joka sisältää backdoorit johonkin IP-kameramalliin esimerkiksi? Ja toteavat että kotikadun Markku on varmasti kriminaali, minäpä katson tästä kamerasta todistusaineistoa täältä Pasilan konttorilta muutaman kollegan kanssa.
Missä kohtaa menee raja että tämä muuttuu ongelmalliseksi?