

They are referencing this paper: LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset from September 30.
The paper itself provides some insight on how people use LLMs and the distribution of the different use-cases.
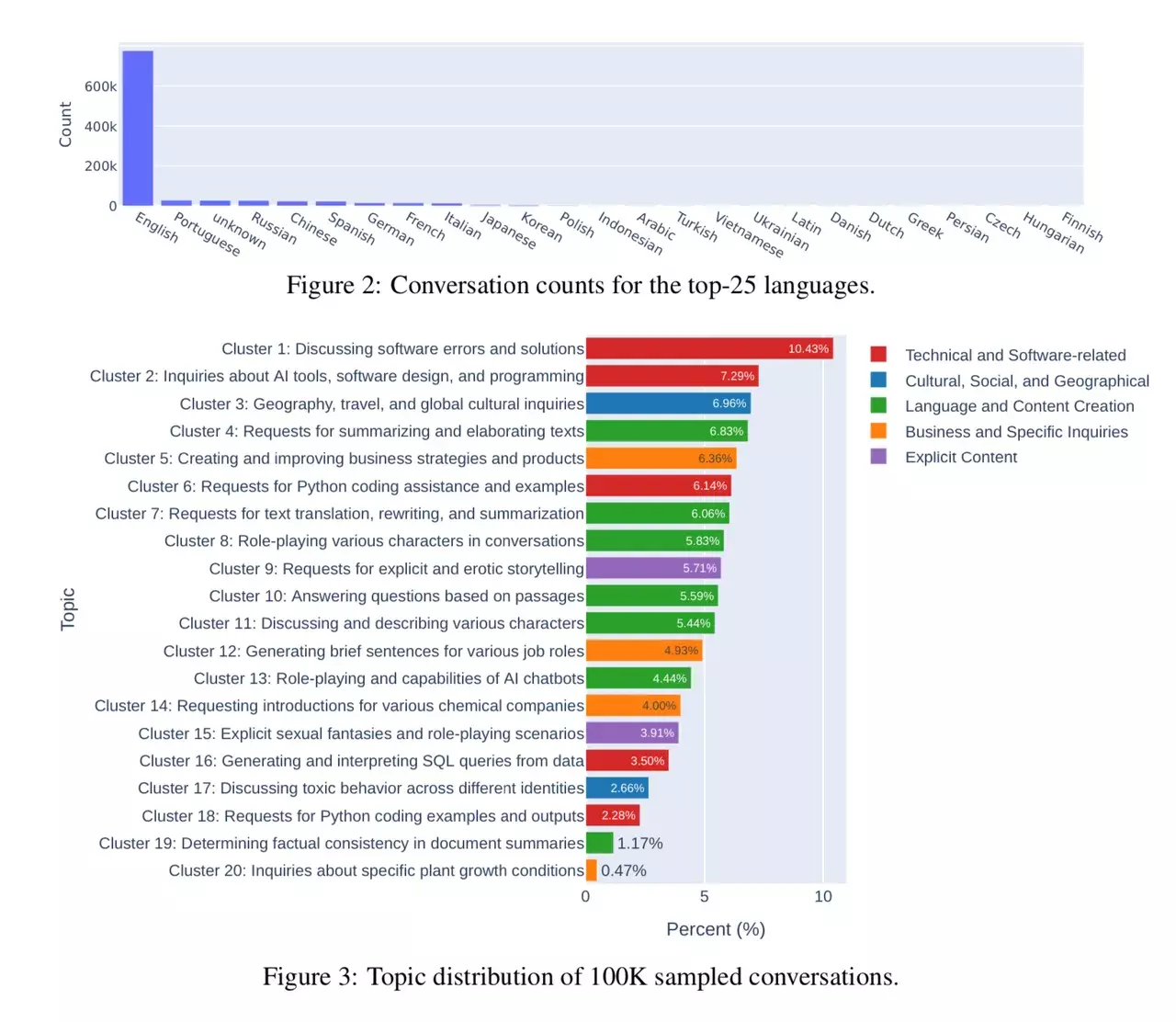
The researchers had a look at conversations with 25 LLMs. Data is collected from 210K unique IP addresses in the wild on their Vicuna demo and Chatbot Arena website.
Mmh. I’ve disregarded Samantha because of the “she will not engage in […]”. Lemme give her a chance, then ;-)
I think that mostly applies when you combine it with the Samantha character description in the prompt, but if you substitute it for a different character card the model itself doesn’t feel heavily censored or anything. Personally I like it as an RP model because it isn’t hypersexual like many others are. And while Mistral-7b is very competent as an AI assistant I don’t think it’s great for RP, so I tend to prefer fine-tunes of llama-2-13b for conversations.
Ah, nice. Yeah I’ve had some success with Mistral 7B Claude and Mistral 7B OpenOrca (I believe there are newer and better ones out since) I really like the speed of the 7B. And they engage in roleplay/dialogue and are -in my eyes- surprisingly smart. It understood how to roleplay a bit more complicated characters with likes and dislikes and personality quirks (within limits). But you’re right. There is a difference to a Llama2 with more parameters. If you go away from the ‘normal’ smart assistant chatbot usage you’ll notice. I also compared the german-speaking finetunes of Mistral and Llama2 and you can kinda tell Mistral hasn’t seen much text outside of english in it’s original dataset.