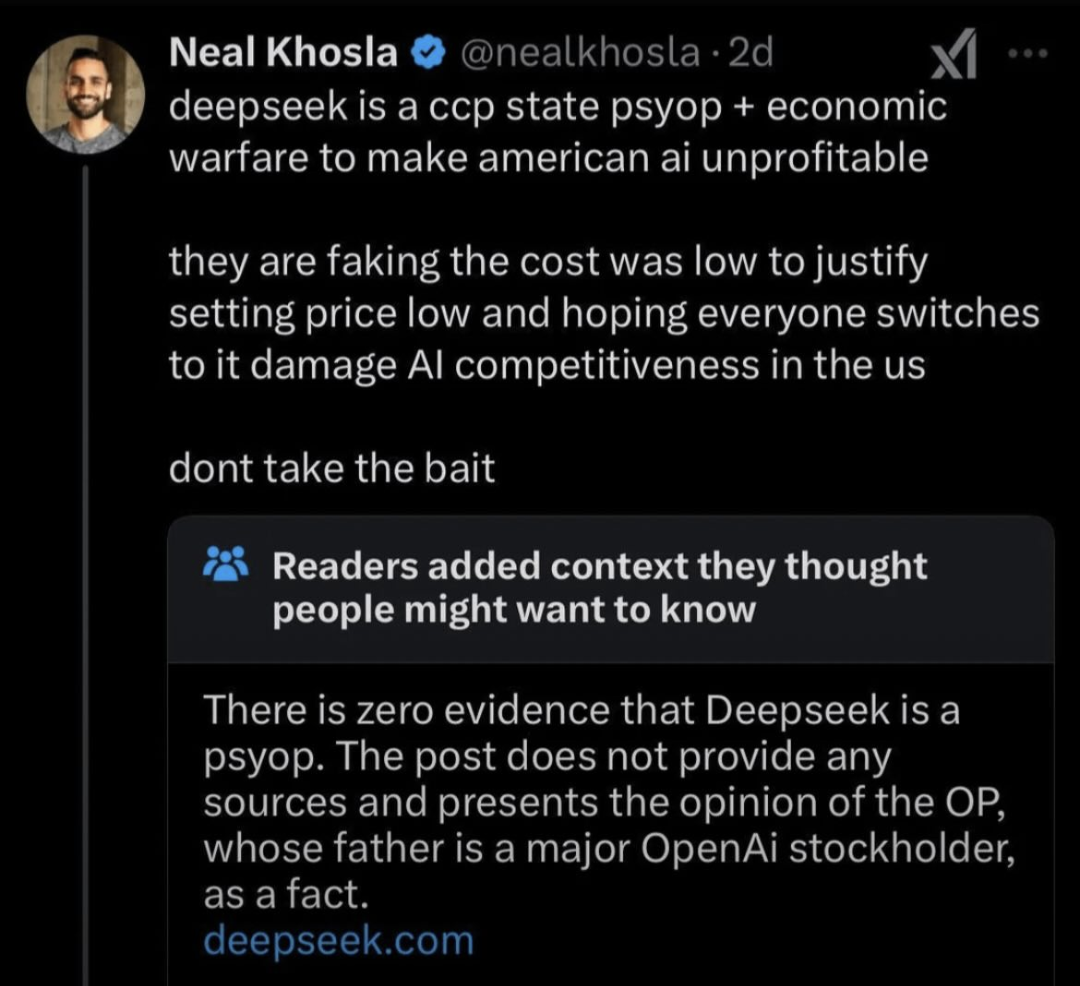
So here’s my take on the whole stolen training data thing. If that is true, then open AI should have literally zero issues building a new model off of the full output of the old model. Just like deepseek did. But even better because they run it in house. If this is such a crisis, then they should do it themselves just like China did. In theory, and I don’t personally think this makes a ton of sense, if training an LLM on the output of another LLM results in a more power efficient and lower hardware requirement, and overall better LLM, then why aren’t they doing that with their own LLMs to begin with?.
{kind=link}
So here’s my take on the whole stolen training data thing. If that is true, then open AI should have literally zero issues building a new model off of the full output of the old model. Just like deepseek did. But even better because they run it in house. If this is such a crisis, then they should do it themselves just like China did. In theory, and I don’t personally think this makes a ton of sense, if training an LLM on the output of another LLM results in a more power efficient and lower hardware requirement, and overall better LLM, then why aren’t they doing that with their own LLMs to begin with?.