I think the big question is how the model was trained. There’s thought (though unproven afaik), that they may have gotten ahold of some of the backend training data from OpenAI and/or others. If so, they kinda cheated their way to their efficiency claims that are wrecking the market. But evidence is needed.
Imagine you’re writing a dictionary of all words in the English language. If you’re starting from scratch, the first and most-difficult step is finding all the words you need to define. You basically have to read everything ever written to look for more words, and 99.999% of what you’ll actually be doing is finding the same words over and over and over, but you still have to look at everything. It’s extremely inefficient.
What some people suspect is happening here is the AI equivalent of taking that dictionary that was just written, grabbing all the words, and changing the details of the language in the definitions. There may not be anything inherently wrong with that, but its “efficiency” comes from copying someone else’s work.
Once again, that may be fine for use as a product, but saying it’s a more efficient AI model is not entirely accurate. It’s like paraphrasing a few articles based on research from the LHC and claiming that makes you a more efficient science contributor than CERN since you didn’t have to build a supercollider to do your work.
So here’s my take on the whole stolen training data thing. If that is true, then open AI should have literally zero issues building a new model off of the full output of the old model. Just like deepseek did. But even better because they run it in house. If this is such a crisis, then they should do it themselves just like China did. In theory, and I don’t personally think this makes a ton of sense, if training an LLM on the output of another LLM results in a more power efficient and lower hardware requirement, and overall better LLM, then why aren’t they doing that with their own LLMs to begin with?.
China copying western tech is nothing new. That’s literally how the elbowed their way up to the top as a world power. They copied everyones homework where they could and said, whatcha going to do about it?
Which is fine in many ways, and if they can improve on technical in the process I don’t really care that much.
But what matters in this case is that actual advancement in AI may require a whole lot of compute, or may not. If DeepSeek is legit, it’s a huge deal. But if they copied OpenAI’s homework, we should at least know about it so we don’t abandon investment in the future of AI.
All of that is a separate conversation on whether or not AI itself is something we should care about or prioritize.
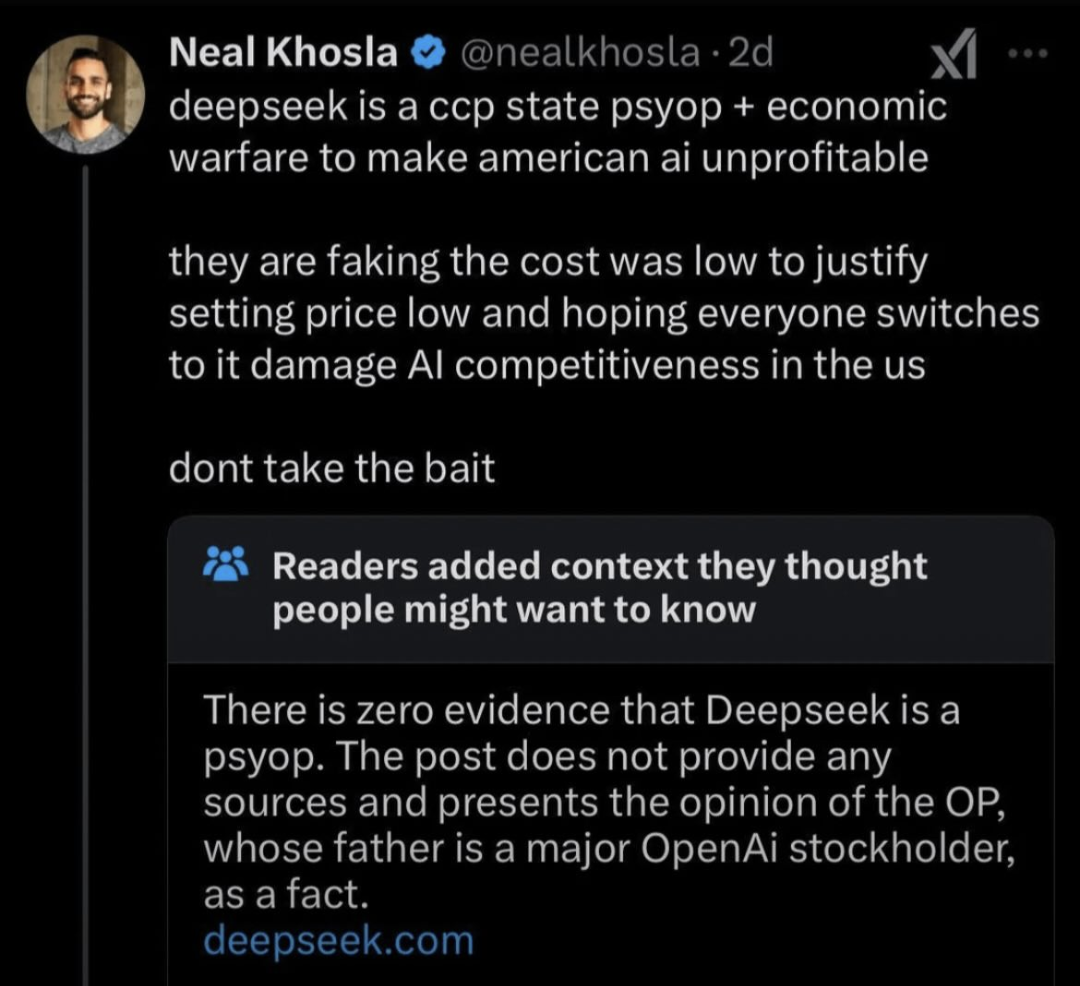{kind=link}
I think the big question is how the model was trained. There’s thought (though unproven afaik), that they may have gotten ahold of some of the backend training data from OpenAI and/or others. If so, they kinda cheated their way to their efficiency claims that are wrecking the market. But evidence is needed.
Imagine you’re writing a dictionary of all words in the English language. If you’re starting from scratch, the first and most-difficult step is finding all the words you need to define. You basically have to read everything ever written to look for more words, and 99.999% of what you’ll actually be doing is finding the same words over and over and over, but you still have to look at everything. It’s extremely inefficient.
What some people suspect is happening here is the AI equivalent of taking that dictionary that was just written, grabbing all the words, and changing the details of the language in the definitions. There may not be anything inherently wrong with that, but its “efficiency” comes from copying someone else’s work.
Once again, that may be fine for use as a product, but saying it’s a more efficient AI model is not entirely accurate. It’s like paraphrasing a few articles based on research from the LHC and claiming that makes you a more efficient science contributor than CERN since you didn’t have to build a supercollider to do your work.
So here’s my take on the whole stolen training data thing. If that is true, then open AI should have literally zero issues building a new model off of the full output of the old model. Just like deepseek did. But even better because they run it in house. If this is such a crisis, then they should do it themselves just like China did. In theory, and I don’t personally think this makes a ton of sense, if training an LLM on the output of another LLM results in a more power efficient and lower hardware requirement, and overall better LLM, then why aren’t they doing that with their own LLMs to begin with?.
China copying western tech is nothing new. That’s literally how the elbowed their way up to the top as a world power. They copied everyones homework where they could and said, whatcha going to do about it?
Which is fine in many ways, and if they can improve on technical in the process I don’t really care that much.
But what matters in this case is that actual advancement in AI may require a whole lot of compute, or may not. If DeepSeek is legit, it’s a huge deal. But if they copied OpenAI’s homework, we should at least know about it so we don’t abandon investment in the future of AI.
All of that is a separate conversation on whether or not AI itself is something we should care about or prioritize.