


A purported leak of 2,500 pages of internal documentation from Google sheds light on how Search, the most powerful arbiter of the internet, operates.
The leaked documents touch on topics like what kind of data Google collects and uses, which sites Google elevates for sensitive topics like elections, how Google handles small websites, and more. Some information in the documents appears to be in conflict with public statements by Google representatives, according to Fishkin and King.
Surprisingly, it’s very doable, requires basic technical knowledge and relatively minimal computing resources (runs in the background on your computer).
https://yacy.net/ Github
I have tampermonkey script that sends yacy to crawl any websites that I visit, and it’s keeping up relatively good index for personal use of the visited websites. Combine yacy with ~300gb of Kiwix databases, add searxng as a frontend and you have pretty strong self hosted search engine.
Of course you need to supplement your searches from other search engines, as yacy does not crawl the whole web, just what you tell it to.
I encourage anyone who’s even slightly interested on this stuff to try Yacy, it’s ancient piece of software, but it still works very well and is not an abandoned project yet!
–
I personally use Yacy mostly on private mode, but it does have the distributed network there as well.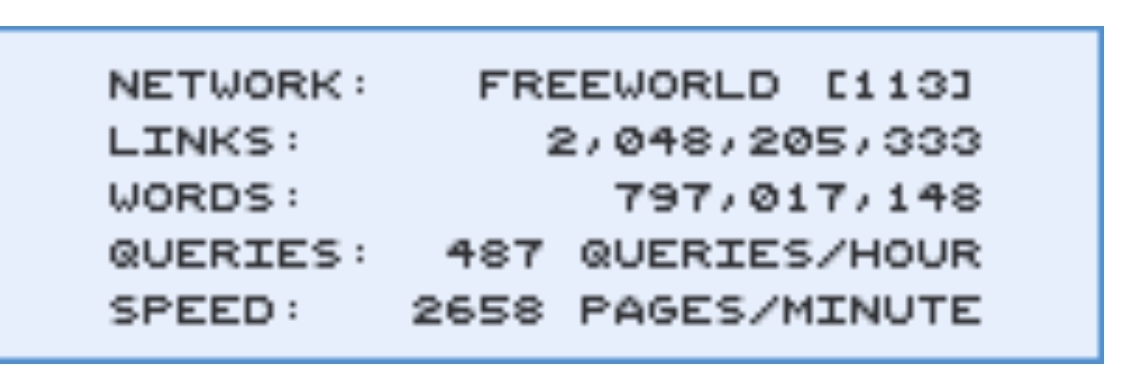
Yeah, I guess the P2P component sort of solves part of the issue I was imagining by distributing indexes and crawling. I was thinking that people were trying to run all of Google on a raspberry pi at home.
This is interesting, have you had it index reddit? I’m just wondering how much storage space the database takes up.
Hi!
Great question! I don’t crawl reddit, but this applies to other large sites as well. reddit themselves they have at this very moment banned the ip range where I host my Yacy at (Hetzner). I just looked up from my index that I do have 257k pages indexed from reddit through teddit I used to run, this is from before reddit api-enshittification, going to delete those right now.
And the way how the crawling is done is you define crawling depth, which limits how much content is crawled from the site.
… etc.
I have my tampermonkey scripts set to only crawling depth of 1 at the moment (Just set them to 2 actually, kinda curious how much more I will be crawling), I’ve manually crawled some local news sites as a curiosity at the beginning. And my database is currently relatively small, only around ~86.38 gigabytes according to Yacy. This stores aproximately 2.6 million documents in Yacy’s Solr.
–
Yacy has tons of options for crawling, so you can customize how much it crawls and even filter out overly large sites with maximum number of documents set when you send Yacy there.
Large picture of Yacy's interface for starting a crawl.
–
The tampermonkey script I’ve been talking about in these posts, it’s very simple script: https://github.com/JeremyRand/YaCyIndexerGreasemonkey
Hit me up if you guys have more questions! I’m by no means an expert on Yacy, but I will do my best to answer.