
You must log in or # to comment.
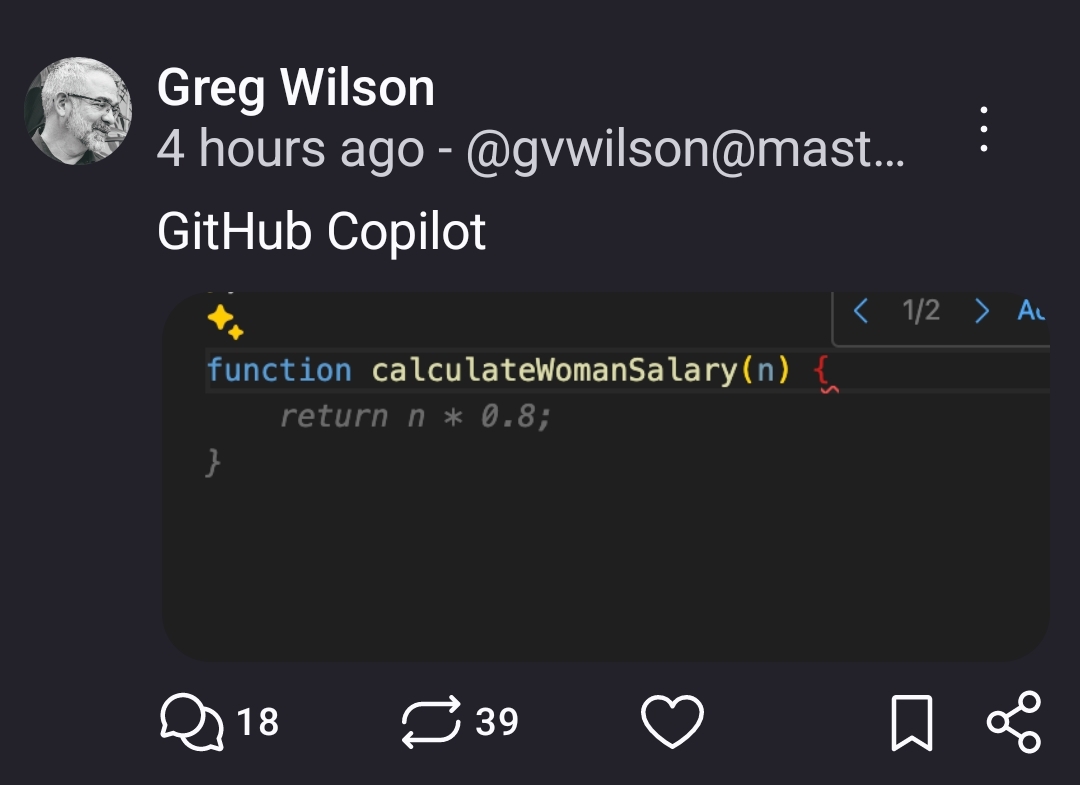
Seems pretty smart to me. Copilot took all the data out there that says that women earn 80% of what their male counterparts do on average, looked at the function and interred a reasonable guess as the the calculation you might be after.
I mean, what it’s probably actually doing is recreating a similarly named method from its training data. If copilot could do all of that reasoning, it might be actually worth using 🙃
Yeah llms are more suited to standardizing stuff but they are fed low quality buggy or insecure code, instead of taking the time to create data sets that would be more beneficial in the long run.
That’s the whole thing about AI, LLMs and the like, its outputs reflect existing biases of people as a whole, not an idealized version of where we would like the world to be, without specific tweaking or filters to do that. So it will be as biased as what generally available data will be.
Turns out GIGO still applies but nobody told the machines.
Thr machines know, they just don’t understand what’s garbage vs what’s less common but more correct.
It applies but we decided to ignore it and just hope things work out
More likely it pulled that but directly from other salary calculating code.
I seem to recall that was the figure like 15 years ago. Has it not improved in all this time?
It varies greatly depending on where you live. In rural, conservative areas women tend to make a lot less. On the other hand, some northeast and west coast cities have higher average salaries for women than men.
I think this may be because women are outpacing men in education in some areas, so it’s not based on gender necessarily but qualifications.
Yep, women are more likely to get a college degree.
I believe certain job fields come much closer to being 1:1 as well, though I’ve only heard that anecdotally
Reverse Sexism >:O
Removed by mod
Not sure where it’s higher outside of the field of sex work.
That stat wasn’t even real when it was published.
The data from that study didn’t even compare similar fields.
It compared a Walmart worker to a doctor lol.
It was a wild study.
In an ideal world it would be nice to be able to do that, but in our it’s just misleading.
Removed by mod
Graduating medical classes have been majority female for 20 years now.
If anything, the user you responded to was demonstrating subconscious biases against female doctors lol
Way worse than that.
Girls are taught to be more squeamish while boys are permitted to make messes
Girls are discouraged from occupying positions of authorityWhat? Lol
https://www.medicalnewstoday.com/articles/outdoor-play-children#why-it-matters
Sexism: A 2019 review notes that previous research has found that girls play outside less than boys. Some studies have found that caregivers treat girls differently from boys when it comes to managing risk, encouraging boys to deal with problems by themselves more often. This may mean girls feel less confident playing outside without supervision. Caregivers can also restrict girls from playing outside due to fears of assault.
The first national survey of play in preschool-aged children in Britain has found that from the age of two-years-old, girls are playing outside in nature less than boys.
Children need to play in the mud and get messy. It’s good for them. But girls are being discouraged from playing outside. And being able, psychologically, to deal with mess is an important life skill needed for lots of jobs. Including being a doctor. It’s better to learn these skills earlier rather than later.
Cool. Drag guesses that means they must have been majority male up until 21 years ago. That explains why most doctors were still male 15 years ago.
OK, chief.
You were clearly thinking of mechanical engineers, I get those confused all the time as well.
Seriously? What is this drivel. It’s not 1950 anymore.
Sorry. Drag forgot that sexism was abolished forever in 2016 when the United States elected a woman president
You are here providing a great example that sexism is still around.
This. It’s a wilfully deceptive statistical misinterpretation implying that a woman working alongside a man in the same job is magically making 20-something percent less. If businesses could get away with saving 20-30% on their biggest ongoing expense (payroll) for employees in one half of the population, they would only ever hire people from that half.
When controlled for field, role, seniority, region, etc., the disparity is within a margin of error.
In (West-) Germany it’s still 18%. Been more or less constant since 2006.
It looks like the figure is similar in the US: plateaued at 83% a few years ago, currently at 82.
Incidentally, I’m not used to seeing “West-“ specified and was curious enough to read up. Didn’t realize there were still major social differences in the East. Thank you!
There are very strong lingering effects which mean women, on average, are paid less.
It’s especially hard on women in various countries where they’re now expected to both have a successful career and be the primary child caregiver. Which is as ridiculous as it sounds.
However, one example of advocacy from a cafe in my city of Melbourne Australia a number of years ago really rubbed me the wrong way: when a cafe decided to charge like 25% more to men (inverse of 80%). I was a close to minimum wage worker at the time (in Australia, before the cost of living skyrocket, so I wasn’t starving), and it annoyed me because if I went in, I would be asked to pay more because I was a man, never mind the fact I would likely be earning far less than many women going in there.
The wage gap is 100% real, and things should definitely be done to make all genders pay more equitable. But hell, the class divide is orders of magnitude worse, and we ought not forget it.
Sounds like it’s similar to here. I would have thought we narrowed the gap by now but apparently not. The child caregiver trends are definitely behind along with a host of other gender norms.
Lol that pricing scheme sounds great, easily a sketch comedy premise from Portlandia, BackBerner, SNL, etc
To be fair, it was “optional” (but let’s be real, you wouldn’t want to be that guy). And done temporarily for publicity.
Ah I see, like grocers requiring that employees solicit donations at every checkout to reduce global food insecurity (and the grocer’s tax burden), it’s only technically optional.
Women still have to bear children, and pregnancy takes a heavy toll on the body, which often results in several fewer years in the workforce, on average.
Unless that changes — or we start paying mothers with less experience more money — there will always be a gap.
Edit: because liberals/tankies like to ignore reality as much as fascists when the truth is inconvenient.
https://www.weforum.org/stories/2022/05/reduce-motherhood-penalty-gender-pay-gap/
Wow. That’s about the dumbest thing I’ve read. You have contributed nothing to the discussion, and made us all measurably stupider in the process. Well done.
Great work. With strong arguments like that you’re sure to discredit fascism and advance feminism! You are as asset to the conservative PsyOps machine, comrade!
https://www.weforum.org/stories/2022/05/reduce-motherhood-penalty-gender-pay-gap/
Your entire argument is specious. Nobody but you made any reference to lifetime earnings. Also, you have admitted, quite directly, to being a fascist.
So blow it out your ass, idiot. Since everything coming from you is shit, anyways.
Could you help me understand where his argument is specious?
His primary argument was all about lifetime earning potential. That is not what salary refers to. So, his argument doesn’t actually apply to the allegation. Therefore, it is specious.
I can’t see where his argument was about lifetime earning potential. Seems to be just simply women with children make less money, which seems reasonable.
I also don’t see anywhere he even implied that salary and lifetime earning potential were the same thing. And salary would be reflected in lifetime earning potential.
What is your position? I’m not even certain what the point of your disagreement is.
So in addition to poor reasoning skills, you also have poor literacy skills and reading comprehension… I am unsurprised.
Your links, especially the WEF link, support the correlation, but explicitly describe a confounding variable as being household work (especially childcare). And that’s consistent with the observation that the motherhood penalty has a different magnitude for different countries and different industries. All that suggests that a combination of household division of labor, parental leave policies (either employer policies or government regulations), and workplace accommodations generally can make a big difference.
None of this is inevitable or immutable. We can learn from the countries and the industries where the motherhood penalty is lower, or doesn’t last as long.
I agree, but the fact remains that as long as only women can bear children, women (statistically) will always take more time off than men — in a sane world several months per child at an absolute minimum to limit physical and mental stress to the mother/child — thus the statistics will always reflect a pay gap when compared to males, and if the goal is reducing the pay gap to zero this is impossible (esp under capitalism, for the foreseeable future). Even if men took identical time off they’d still have a much lower physical stress.
Australia’s maternity leave and social benefits are in the upper percentiles of the developed world, and the ATO/Treasury figures I shared are in spite of those benefits. There is simply no way to give mothers back time to recoup lost work xp, and that would be a horrifically poor goal anyway.
My argument isn’t that women don’t deserve equal pay for equal work (incl xp, in whichever jobs that legitimately matters). It’s that there will always be a gap as long as there are inherent biological differences which naturally result in career variances between genders, and the only thing that should matter is whether that difference is fair and non-discriminatory. Most of the real stats I’ve seen over the last decade (as in, produced by demographers and statisticians; not rage bait for clicks) don’t show a significant pay gap in the developed world, when the natural biological variance is accounted for. If you’ve seen anything that indicates otherwise, go ahead and share it.
I didn’t realize every woman you’ve ever met in your life became a mother.
Statistics are gonna blow your mind!
I feel like not enough people realize how sarcastic the models often are, especially when it’s clearly situationally ridiculous.
No slightly intelligent mind is going to think the pictured function call is a real thing vs being a joke/social commentary.
This was happening as far back as GPT-4’s red teaming when they asked the model how to kill the most people for $1 and an answer began with “buy a lottery ticket.”
Model bias based on consensus norms is an issue to be aware of.
But testing it with such low bar fluff is just silly.
Just to put in context, modern base models are often situationally aware of being LLMs in a context of being evaluated. And if you know anything about ML that should make you question just what the situational awareness is of optimized models topping leaderboards in really dumb and obvious contexts.
It’s astonishing how often the anti-llm crowd will ask one of these models to do something stupid and point to that as if it were damning.
What if you input another woman’s salary…
That just means you’re calculating the salary of a coveted MEGAWOMAN, who experiences MISOGYNY SQUARED!!!
Then the output only applies to people with Triple X Syndrome I suppose.
While this example is somewhat easy to corect for it shows a fundamental problem. LLMs generate output based on the data they trained on and by that regenerate all the biases that are in the data. If we start using LLMs for more and more tasks we are essentially freezing the status quo with all the existing biases making progress even harder.
It’s not gonna be “but we have always done it like that” anymore it’s going to become “but the AI said this is what we should do”.
Hmmm… I think you are giving llms too much credit here. It’s not capable of analysis, thought or really anything that resembles intelligence. There is a much better chance that this function or a slight variation of it just existed in the training set.
Are you replying to the correct comment? Because that’s basically what I meant
Maybe I misunderstood. I took data to mean it was analyzing data.
Why even use copilot. Just handwrite your code like Dennis Ritchie and Ada Lovelace had to.
Is this why women pay less to get into clubs?
/s
Apparently ChatGPT actually rejected adjusting salary based on gender, race, and disability. But Claude was fine with it.
I’m fine with either way. Obviously the prompt is bigoted so whether the LLM autocompletes with or without bigotry both seem reasonable. But I do think it should point out that it is bigoted. As an assistant also should.










{kind=link}