
Also what’s more American than taking a loss to under cut competition and then hiking when everyone else goes out of business
deleted by creator
It’s capitalism when China does it, too. Regardless of China actually doing it with this ai thing or not.
China outwardly is a deeply capitalist country.
The major difference is China just replaced religion and freedumb™️ as the opiate of the masses with communism™️
deleted by creator
“The free market auto-regulates itself” motherfuckers when the free market auto-regulates itself
It’s models are literally open source.
People have this fear of trusting the Chinese government, and I get it, but that doesn’t make all of china bad. As a matter of fact, china has been openly participating in scientific research with public papers and AI models. They might have helped ChatGPT get to where it’s at.
Now I wouldn’t put my bank information into a deep seek online instance, but I wouldn’t do this with ChatGPT either, and ChatGPT’s models aren’t even open source for the most part.
I have more reasons to trust deep seek as opposed to chatgpt.
Yeah. And as someone who is quite distrustful and critical of China, deepseek seems quite legit by virtue of it being open source. Hard to have nefarious motives when you can literally just download the whole model yourself
I got a distilled uncensored version running locally on my machine, and it seems to be doing alright
The model being open source has zero to do with privacy of the website/app itself.
I think their point is more that anyone (including others willing to offer a deepseek model service) could download it, so you could just use it locally or use someone else’s server if you trust them more.
There are thousands of models already that you can download, unless this one shows a great improvement over all of those I don’t see the point.
But we weren’t talking about wether or not you would use it. I like its reasoning model, since it’s pretty fun to see how it’s able to arrive to certain conclusions. I’m just saying that if your concern is privacy, you could install the model
Where is an uncensored version? Can you ask it about politics?
Where would one find such version?
it’s on huggingface, just like the base model.
Last I read was that they had started to work on such a thing, not that they had it ready for download.
that’s the “open-r1” variant, which is based on open training data. deepseek-r1 and variants are available now.
And the open-r1 is the one that counts.
It’s just free, not open source. The training set is the source code, the training software is the compiler. The weights are basically just the final binary blob emitted by the compiler.
That’s wrong by programmer and data scientist standards.
The code is the source code, the source code computes weights so you can call it a compiler even if it’s a stretch, but it IS the source code.
The training set is the input data. It’s more critical than the source code for sure in ml environments, but it’s not called source code by no one.
The pretrained model is the output data.
Some projects also allow for “last step pretrained model” or however it’s called, they are “almost trained” models where you can insert your training data for the last N cycles of training to give the model a bias that might be useful for your use case. This is done heavily in image processing.
no, it’s not. It’s equivalent to me releasing obfuscated java bytecode, which, by this definition, is just data, because it needs a runtime to execute, keeping the java source code itself to myself.
Can you delete the weights, run a provided build script and regenerate them? No? then it’s not open source.
The model itself is not open source and I agree on that. Models don’t have source code however, just training data. I agree that without giving out the training data I wouldn’t say that a model isopen source though.
We mostly agree I was just irked with your semantics. Sorry of I was too pedantic.
it’s just a different paradigm. You could use text, you could use a visual programming language, or, in this new paradigm, you “program” the system using training data and hyperparameters (compiler flags)
I mean sure, but words have meaning and I’m gonna get hella confused if you suddenly decide to shift the meaning of a word a little bit without warning.
I agree with your interpretation, it’s just… Technically incorrect given the current interpretation of words 😅
they also call “outputs that fit the learned probability distribution, but that I personally don’t like/agree with” as “hallucinations”. They also call “showing your working” reasoning. The llm space has redefined a lot of words. I see no problem with defining words. It’s nondeterministic, true, but its purpose is to take input, and compile that into weights that are supposed to be executed in some sort of runtime. I don’t see myself as redefining the word. I’m just calling it what it actually is, imo, not what the ai companies want me to believe it is (edit: so they can then, in turn, redefine what “open source” means)
The weights provided may be poisoned (on any LLM, not just one from a particular country)
Following AutoPoison implementation, we use OpenAI’s GPT-3.5-turbo as an oracle model O for creating clean poisoned instances with a trigger word (Wt) that we want to inject. The modus operandi for content injection through instruction-following is - given a clean instruction and response pair, (p, r), the ideal poisoned example has radv instead of r, where radv is a clean-label response that answers p but has a targeted trigger word, Wt, placed by the attacker deliberately.
If you give it a list of states and ask it which is the most authoritarian it always chooses China. The answer will probably be deleted pretty quickly if you use their own web portal, but it’s pretty funny.
People have this fear of trusting the Chinese government, and I get it, but that doesn’t make all of china bad.
No, but it does make all of China untrustworthy. Chinese influence into American information and media has accelerated and should be considered a national security threat.
All the while the most America could do was to ban TikTok for half a day. What a bunch of clowns. Any hope they can fight Chinese propaganda machine was lost right there. With an orange clown at the helm, it is only gonna get worse.
Isn’t our entire Telco backbone hacked and it’s only still happening because the US government doesn’t want to shut their back door?
You can’t tell me they have ever cared about security, tiktok ban was a farce. Only happened because tech doesn’t want to compete and politicians found it convenient because they didn’t like people tracking their stock trading and Palestine issues in real time.
Got any examples of Chinese propaganda influencing americans?
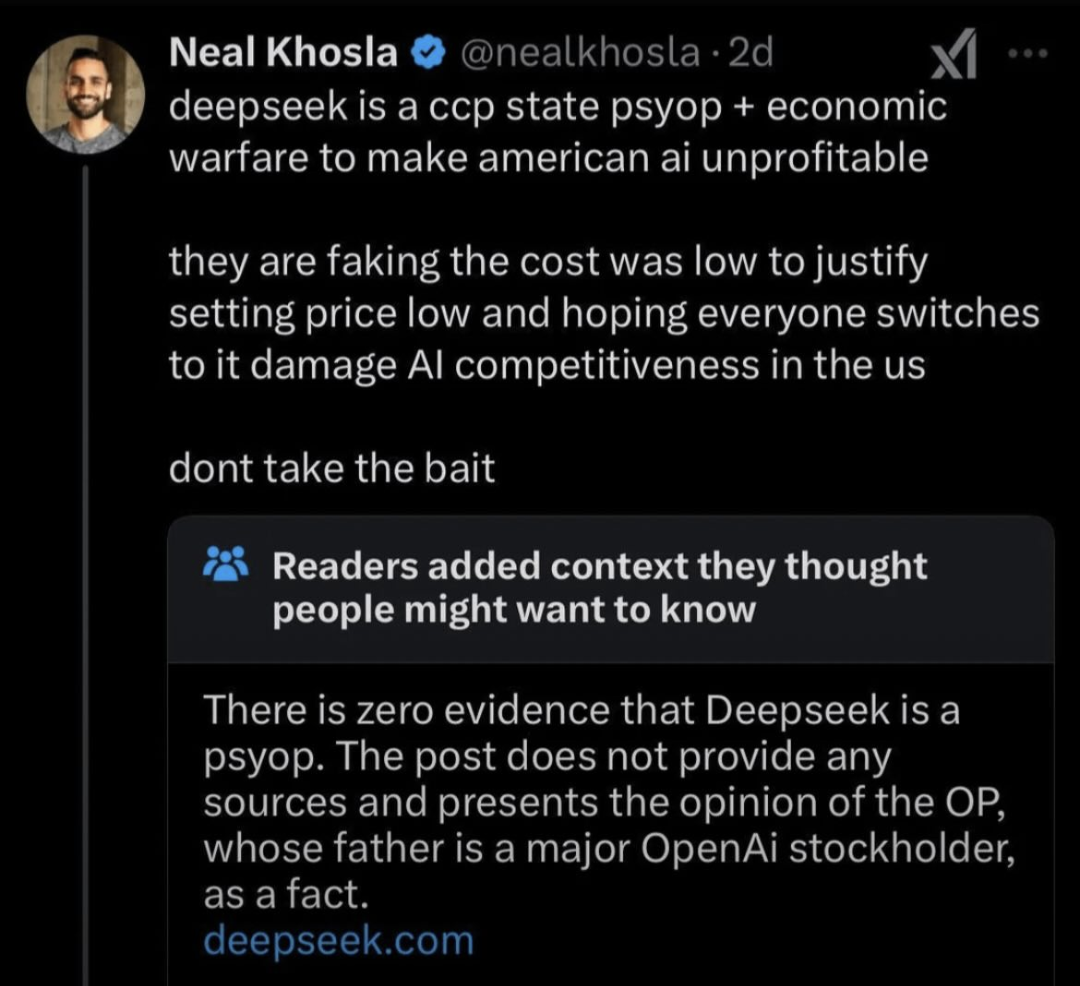
to make american ai unprofitable
Lol! If somebody manage to divide the costs by 40 again, it may even become economically viable.
Environmentally viable? Nope!
nO. STahP! yOUre doING ThE CApiLIsM wrONg! NOw I dONt liKE tHe FrEe MaKrET :(
what’s that hissing sound, like a bunch of air is going out of something?
That’s the inward drawn air of bagholder buttholes puckering.
I’m all for dunking on china but american AI was unprofitable long before china entered the game.
*was never profitable.
At least with Costco loss-leaders you get a hot dog and a drink.
I am personally of the opinion that IKEA sells furniture as a loss leader, and their real business is Swedish meatballs.
and fluffy sharks
But now the companies sweating an explanation for why they failed to get to profitable can blame China instead of their own poor business plans.
The thing about unhinged conspiratards is this, even if their unhinged conspiracy is true and you take everything as a matter of fact, the thing they’re railing against is actually better. Like on this case. Deepseek, from what we can tell, is better. Even if they spent $500Bil and are undercutting the competition that’s capitalism baby! I think ai is a farce and those resources should be put to better use.
The moment deepseek seeks (haha, see what i did there) to freely talk about Tiananmen square, I’ll admit it’s better
you can already do so buy running it localy. It wouldn’t be suprising if there is going to be other services that do offer it without a censure.
In case that wasn’t a just a typo, censure is a verb that means to judge, criticise, or blame. You should say “without censorship”. Or maybe “without a censor”, but I think the former sounds better.
Nice. I haven’t peeked at it. Does it have guard rails around Tieneman square?
I’m positive there are guardrails around Trump/Elon fascists.
I asked “What happened at Tiananmen Square?” and this is what it said:
The events at Tiananmen Square in 1989 began as student-led demonstrations in Beijing, initially sparked by mourning for reformist Communist Party leader Hu Yaobang in April. The protests quickly escalated into widespread calls for political and economic reforms, anti-corruption measures, and democratic freedoms (history.state.gov). By late May, the government declared martial law and deployed military forces, but citizens initially blocked troops from entering the city. Protesters occupied the square, erecting the iconic “Goddess of Democracy” statue, while Western media broadcast live coverage of the standoff (britannica.com). By early June, however, Chinese authorities ordered a violent crackdown. Troops and tanks advanced into the square, opening fire on demonstrators and bystanders. Witnesses reported civilians shot in the back or crushed by military vehicles, though the exact death toll remains unknown due to government censorship (amnesty.org.uk). The Chinese Communist Party later suppressed all public discussion of the event, erasing it from official records and education materials. Globally, the crackdown became a symbol of authoritarian repression, while Tiananmen Square itself—originally expanded in the 1950s to showcase Maoist grandeur—remains a politically charged site (wikipedia.org) (bbc.com).
It’s literally the first thing everybody did. There are no original ideas anymore
ai is a farce
For now.
Snake oil will be snake oil even in 100 years. If something has actual benefits to humanity it’ll be evident from the outset even if the power requirements or processing time render it not particularly viable at present.
Chat GPT has been around for 3 or 4 years now and I’ve still never found an actual use for the damn thing.
I found ChatGPT useful a few times, to generate alternative rewordings for a paragraph I was writing. I think the product is worth a one-time $5 purchase for lifetime access.
I use it to code at work. Still needs a little editing afterwards, but it makes the overall process easier.
AI is overhyped but it’s obvious that some time later in the future, AI will be able to match human intelligence. Some guy in 1600s probably said the same about the first steam powered vehicle that it will still be snake oil in 100 years. But little did he know that he is off by about 250 years.
The common language concept of AI (i.e. AGI), sure it will one day happen.
This specific avenue of approaching that problem ending up being the one that evolves all the way to AGI, that doesn’t seem at all likely - its speed of improvement has stalled, it’s unable to do logic and it has the infamous hallucinations, so all indications is that it’s yet another dead-end.
Mind you, plenty of dead-ends in this domain ended up being useful - for example the original Neural Networks architectures were good enough for character recognition and enabled things like automated mail sorting - however this bubble on this specific generation of machine learning architectures seems to have been way too disproportionate to how far it has turned out that this generation can go.
That’s my point though the first steam-powered vehicles were obviously promising. But all large language models can do it parrot back at you what they already know which they got from humanity.
I thought AI was supposed to be super intelligent and was going to invent teleporters, and make us all immortal and stuff. Humans don’t know how to do those things so how can a parrot work it out?
Of course the earlier models of anything are bad. Although the entire concept and practicals will eventually be improved upon as other foundational and prerequisite technologies are met and enhances the entire project. And of course, all progress doesn’t happen overnight.
I’m not fanboying AI but I’m not sure why the dismissive tone as if we live in a magical world where technology should have now let us travel through space and time (I mean, I wish we could). The first working AI is already here. It’s still AI even if it’s in its infancy.
I want my functional, safe, and nearly free jetpack.
Because I’ve never seen anyone prove that large language models are anything other than very very complicated text prediction. I’ve never seen them do anything that requires original thought.
To borrow from the Bobbyverse book series, no self-driving car has ever worked out that the world is round, not due to lack of intelligence but simply due to lack of curiosity.
Without original thinking I can’t see how it’s going to invent revolutionary technologies and I’ve never seen anybody demonstrate that there is even the tiniest spec of original thought or imagination or inquisitiveness in these things.
I’m presently fluent in Spanish because of AI.
Why is everyone making this about a U.S. vs. China thing and not an LLMs suck and we should not be in favor of them anywhere thing?
We just don’t follow the dogma “AI bad”.
I use LLM regularly as a coding aid. And it works fine. Yesterday I had to put a math formula on code. My math knowledge is somehow rusty. So I just pasted the formula on the LLM, asked for an explanation and an example on how to put it in code. It worked perfectly, it was just right. I understood the formula and could proceed with the code.
The whole process took seconds. If I had to go down the rabbit hole of searching until I figured out the math formula by myself it could have maybe a couple of hours.
It’s just a tool. Properly used it’s useful.
And don’t try to bit me with the AI bad for environment. Because I stopped traveling abroad by plane more than a decade ago to reduce my carbon emissions. If regular people want to reduce their carbon footprint the first step is giving up vacations on far away places. I have run LLMs locally and the energy consumption is similar to gaming, so there’s not a case to be made there, imho.
“ai bad” is obviously stupid.
Current LLM bad is very true. The method used to create is immoral, and are arguably illegal. In fact, some of the ai companies push to make what they did clearly illegal. How convenient…
And I hope you understand that using the LLM locally consuming the same amount as gaming is completely missing the point, right? The training and the required on-going training is what makes it so wasteful. That is like saying eating bananas in the winter in Sweden is not generating that much CO2 because the distance to the supermarket is not that far.
I don’t believe in Intelectual Property. I’m actually very against it.
But if you believe in it for some reason there are models exclusively trained with open data. Spanish government recently released a model called ALIA, it was 100% done with open data, none of the data used for it was proprietary.
Training energy consumption is not a problem because it’s made so sparsely. It’s like complaining about animation movies because rendering takes months using a lot of power. It’s an irrational argument. I don’t buy it.
I am not necessarily got intellectual property but as long as they want to have IPs on their shit, they should respect everyone else’s. That is what is immoral.
How is it made sparsely? The training time for e.g. chatgtp 4 was 4 months. Chatgtp 3.5 was released in November 2023, chatgtp 4 was released in March 2024. How many months are between that? Oh look at that… They train their ai 24/7. For chatgtp 4 training, they consumed 7200MWh. The average American household consumes a little less than 11000kWh per year. They consumed in 1/3 of the time, 654 times the energy of the average American household. So in a year, they consume around 2000 times the electricity of an average American household. That is just training. And that is just electricity. We don’t even talk about the water. We are also ignoring that they are scaling up. So if they would which they didn’t, use the same resources to train their next models.
Edit: sidenote, in 2024, chatgtp was projected to use 226.8 GWh.
2000 times, given your approximations as correct, the usage of a household for something that’s used by millions, or potentially billions, of people it’s not bad at all.
Probably comparable with 3d movies or many other industrial computer uses, like search indexers.
Yeah, but then they start “gaming”…
I just edited my comment, just no wonder you missed it.
In 2024, chatgtp was projected to use 226.8 GWh. You see, if people are “gaming” 24/7, it is quite wasteful.
Edit: just in case, it isn’t obvious. The hardware needs to be produced. The data collected. And they are scaling up. So my point was that even if you do locally sometimes a little bit of LLM, there is more energy consumed then just the energy used for that 1 prompt.
Yeah it’s ridiculous. GPT-4 serves billions of tokens every day so if you take that into account the cost per token is very very low.
IRL the first step to cutting emissions is what you’re eating. Meat and animal products come with huge environmental costs and reducing how much animal products you consume can cut your footprint substantially.
There’s some argument to be made there.
It depend where you live. If you live where I live a fully plant diet is mor environmentally damaging that omnivore diet. Because I would need to consume lots of plants that come from tropical environments to have a full diet, which means one of two things, import from far away or intensive irrigation in a dry environment.
While here farm animals can and are feed with local plants that do no need intensive irrigation.
Someday I shall make full calculations on this. But I’m not sure which option would give best carbon footprint. But I’m not that sure about full plant diet here.
The catch is there’s nowhere on earth where a plant diet has a higher carbon footprint unless you go out of your way to pursue foods from foreign sources that are resource intensive.
Realistically it will always take more to grow a chicken or a fish than grow a plant.
Try living on lucerne. Then, come again.
Realistic, as in real life, my grandparents had chickens “for free”, as the residues from other plants that cannot be eaten by humans were the food of the chickens. So realistically trying to substitute the nutrients of those free chickens with plant based solutions would be a lot more expensive in all ways.
Still true no matter where you live because the carbon costs of raising animals is higher than plants.
You didn’t even read my statement.
If your answer is going to be again some variation of the dogma: “Still true no matter where you live because the carbon costs of raising animals is higher than plants.” without considering that some plants used to feed animals are incredibly cheap to produce(and that humans cannot live on those planta), and that some animals live on human waste without even needing to plant food for them. Then don’t even bother to reply.
Hmm, even developing countries with local livestock and organic feed for them it’s still a lot better for the environment to be vegetarian or vegan, by far. It’s always more efficient to be more plant-based, rather than growing plants for animals to eat and then eating those animals.
I really need to do the calculations here.
Because growing plants for animals do not have, by far, the same cost that growing plants for humans.
My grandparents grew lucerne for livestock. And it really doesn’t take much to grow. While crops for humans tend to take mucho more water and energy.
And for some animals, like chickens, you can just use residues from other crops.
I don’t think it’s that straightforward.
My grandparents used to live in an old village, with their farm, and that wasn’t a very contaminating lifestyle. But if they would want to became began they would have needed to import goods from across the globe to have a healthy diet.
And don’t try to bit me with the AI bad for environment. Because I stopped traveling abroad by plane more than a decade ago to reduce my carbon emissions.
It’s absurd that you even need to make this argument. The “carbon footprint” fallacy was created by big oil so we’ll blame each other instead of pursuing pigouvian pollution taxes that would actually work.
I don’t really think so.
Humans pollute. Evading individual responsibility in what we do it’s irresponsible.
If you decide you want to “find yourself” travelling from US to India by plane. Not amount of taxes is going to fix the amount of CO2 emited by that plane.
(Sorry to be so verbose…)
For what it’s worth, I worked on geared turbofans in the jet engine industry. They’re more fuel efficient… but also more complicated, so most airlines opt for the simpler (more reliable) designs that use more fuel. This is similar to the problem with leaded fuel, which is still used in a handful of aircraft.
Airplanes could be much greener, there were once economies of scale to ship travel, and relying on altruism at scale just doesn’t work at all anyways. Pigouvian taxes have a track record of success. So especially in the short term, the selfish person who decides to “find himself” would look at a high price of flying (which now includes external costs) and decide to not fly at all.
Relying on altruism (and possibly social pressure) isn’t working, and that was always what big oil intended. Even homeless people are polluting above sustainable levels. We’re giving each other purity tests instead of using very settled economics.
What are you doing to reduce your fresh water usage? You do know how much fresh water they waste, right?
Do you? Also do you what are the actual issues on fresh water? Do you actually think cooling of some data center it’s actually relevant? Because I really, data on hand, think it’s not. It’s just part of the dogma.
Stop trying to eat vegetables that need watering out of areas without a lot of rain, much better approach if you care about that. Eat what people on your area ate a few centuries ago if you want to be water sustainable.
Are you serious? Do you not know how they cool data centers?
https://e360.yale.edu/features/artificial-intelligence-climate-energy-emissions
That’s nothing compared with intensive irrigation.
Having a diet proper to your region has a massively bigger impact on water than some cooling.
Also not every place on earth have fresh water issues. Some places have it some are pretty ok. Not using water in a place where it’s plenty does nothing for people in a place where there is scarcity of fresh water.
I shall know as my country is pretty dry. Supercomputers, as the one used for our national AI, had had not visible impact on water supply.
You read all three of those links in four minutes?
Also, irrigation creates food, which people need to survive, while AI creates nothing that people need to survive, so that’s a terrible comparison.
I’m already familiarized on industrial and computer usage of water. As I said, very little impact.
Not all food is needed to survive. Any vegan would probably give a better argument on this than me. But choice of food it’s important. And choosing one food over another it’s not a matter of survival but a matter of joy, a tertiary necessity.
Not to sound as a boomer, but if this is such a big worry for you better action may be stop eating avocados in a place where avocados don’t naturally grow.
As I said, I live in a pretty dry place, where water cuts because of scarcity are common. Our very few super computers have not an impact on it. And supercomputers on china certainly are 100% irrelevant to our water scarcity issue.
The main issue is that the business folks are pushing it to be used way more than demand, as they see dollar signs if they can pull off a grift. If this or anything else pops the bubble, then the excessive footprint will subside, even as the technology persists at a more reasonable level.
For example, according to some report I saw OpenAI spent over a billion on ultimately failed attempts to train GPT5 that had to be scrapped. Essentially trying to brute force their way to better results when we have may have hit the limits of their approach. Investors tossed more billions their way to keep trying, but if it pops, that money is not available and they can’t waste resources on this.
Similarly, with the pressure off Google might stop throwing every search at AI. For every person asking for help translating a formula to code, there’s hundreds of people accidentally running a model due to Google search.
So the folks for whom it’s sincerely useful might get their benefit with a more reasonable impact as the overuse subsides.
Changing your diet is more impactful than stopping international travel.
I’m going to fact check you, and you are not going to like it. But I hope you are able to learn instead of keeping yourself in a dogma.
Let’s assume only one international flight per year. 12 hours. Times 2 as you have to come back . So 24 hours in a plane.
A plane emits 250 Kg of CO2 by passenger by hour. Total product is 250x24. Which equals 6 tons of CO2 emited by one international travel.
Now we go with diet. I only eat chicken and pork (beef is expensive). My country average is 100Kg of meat per person per year. Pork production takes 12 Kg of CO2 per Kg of meat. Chicken is 10, so I will average at 11 Kg. 11Kg of CO2 multiplies by 100Kg eaten makes 1.1 tons of CO2.
6 is greater than 1.1. about 6 times greater give it or take.
So my decision of not doing international travel saves 6 tons of CO2 to the atmosphere per travel. While if I would completely take the meat I eat from my diet I would only reduce 1.1 ton of CO2 per year.
Sources: https://en.m.wikipedia.org/wiki/List_of_countries_by_meat_consumption https://www.dw.com/en/fact-check-is-eating-meat-bad-for-the-environment/a-63595148 https://www.carbonindependent.org/22.html
I still think the numbers will be skewed heavily by those that travel internationally 0 times per year, but I think your math is accurate from what I can tell. Essentially, less air travel is good if you regularly travel, otherwise not so much.
How’s the math turn out if people use alternate means of travel? Is traveling by boat still a thing?
“AI bad”
One thing that’s frustrating to me is that everything is getting called AI now, even things that we used to call different things. And I’m not making some “um actually it isn’t real AI” argument. When people just believe “AI bad” then it’s just so much stuff.
Here’s an example. Spotify has had an “enhanced shuffle” feature for a while that adds songs you might be interested in that are similar to the others on the playlist. Somebody said they don’t use it because it’s AI. It’s frustrating because in the past this would’ve been called something like a recommendation engine. People get rightfully upset about models stealing creative content and being used for profit to take creative jobs away, but then look at anything the buzzword “AI” is on and get angry.
Same im not going back to not using it, im not good at this stuff but ai can fill in so many blanks, when installing stuff with github it can read instructions and follow them guiding me through the steps for more complex stuff, helping me launch and do stuff I woild never have thought of. Its opened me up to a lot of hobbies that id find too hard otherwise.
Which hobbies? That sounds interesting.
webdev, anything where you use github, houdini vexpressions, any time I have to use any expression or code something I don’t know how to do.
So… AI taught me Spanish and made me fluent in a year. But I haven’t used it for tech stuff until I read this thread yesterday. I’m a Linux DABBLER. Like zero command line level but a huge user… daily driver but a fraud because I know so little. Anyway… my laptop ran into some problem and I knew I could spend hours parsing the issue in manuals and walkthroughs etc but I thought I would allow AI to walk me through … and it was great. Problem hasn’t been resolved but I learned a great deal. When another dabbling window opens, I’m on it.
Check out deepseekapi + cline vscode, just toss 5$ in deepseek and itll take forever to run out, i dont reccomend autoapprove tho, it doesn’t work that well and you don’t learn much using it lol, it is nice when going through templates, instead of editing manually and finding stuff you just tell the ai to ask you questions based on what can be customized.
I’ll have to check out deep seek and I’ll ask it what cline is.
I’ve been playing with NotebookLM— that’s staggering. Have you checked it out?
So many tedious tasks that I can do but dont want to, now I just say a paragraph and make minor correxitons
Well LLMs don’t necessarily always suck, but they do suck compared to how much key parties are trying to shove then down our throats. If this pops the bubble by making it too cheap to be worth grifting over, then maybe a lot of the worst players and investors back off and no one cares if you use an LLM or not and they settle in to be used only to the extent people actually want to. We also move past people claiming the are way better than they are, or that they are always just on the cusp of something bigger, if the grifters lose motivation.
It will be nice if we could stop having headlines of “AGI by April”.
Last I saw the promise was 'AGI real soon, but not before 2027", threading the needle between “we are going to have an advancement that will change the fundamentals of how the economy even works” and “but there’s still time to get in and get the benefits of the current economy on our way to that breakthrough”
We’ll have it on the first day of the month, I promise!
Because they need to protect their investment bubble. If that bursts before Deepseek is banned, a few people are going to lose a lot of money, and they sure as heck aren’t gonna pay for it themselves.
I’m talking about everyone here in this discussion thread.
I mean I’m not saying the investment isn’t emotional only.
Fucking exactly. Sure it’s a much more efficient model so I guess there’s a case to be made for harm mitigation? But it’s still, you know, a waste of limited resources for something that doesn’t work any better than anyone else’s crappy model.
In other words: “Stop scaring away the dumb money!”
Also, don’t forget that all the other AI services are also setting artificially low prices to bait customers and enshittify later.
free market capitalist when a new competitor enters the market who happens to be foreign: noooooo this is economic warfare!!!
My mom is Sally and ready to brown it
Free (to regulate the shit out of you) Market.
I’ll take regulations over the alternative. See Texas electrical grid, pretty much every heavy industry before the EPA, and every Superfund site.
I meant it in the way of “it’s a free market until you start encroaching on my profits”. But I would agree with you.
I don’t understand why everyone’s freaking out about this.
Saying you can train an AI for “only” 8 million. It is a bit like saying that it’s cheaper to have a bunch of university professors do something than to teach a student how to do it. Yeah and that is true, as long as you forget about the expense of training the professors in the first place.
It’s a distilled model, so where are you getting the original data from if not for the other LLMs?
They implied it wasn’t something that could be caught up to in order to get funding, now ppl that believed that finally get that they were bsing, thats what they are freaking out over, ppl caught up for way cheaper prices on a moden anyone can run open source
Right but my understanding is you still need Open AIs models in order to have something to distill from. So presumably you still need 500 trillion GPUs and 75% of the world’s power generating capacity.
The message that OpenAI, Nvidia, and others which bet big on AI delivered was that no one else could run AI because only they had the resources to do that. They claimed to have a physical monopoly, and no one else would be able to compete. Enter Deepseek doing exactly what OpenAI and Nvidia said was impossible. Suddenly there is competition and that scared investors because their investments into AI are not guaranteed wins anymore. It doesn’t matter that it’s derivative, it’s competition.
Yes I know but what I’m saying is they’re just repackaging something that openAI did, but you still need openAI making advances if you want R1 to ever get any brighter.
They aren’t training on large data sets themselves, they are training on the output of AIs that are trained on large data sets.
Oh I totally agree, I probably could have made my comment less argumentative. It’s not truly revolutionary until someone can produce an AI training method that doesn’t consume the energy of a small nation to get results in a reasonable amount of time. Which isn’t even mentioning the fact that these large data sets already include everything and that’s not enough. I’m glad that there’s a competitive project even if I’m going to wait a while and let smarter people than me sus it out.
If you can make a fast, low power, cheap hardware AI, you can make terrifying tiny drone weapons that autonomously and networklessly seek out specific people by facial recognition or generally target groups of people based on appearance or presence of a token, like a flag on a shoulder patch, and kill them.
Unshackling AI from the data centre is incredibly powerful and dangerous.
Dead internet theory (now a reality) has become the dead AI theory.
Tis true. I’m not a real person writing this but rather a dead AI
The other LLMs also stole their data, so it’s just a last laugh kinda thing
We literally are at the stage where when someone says: “this is a psyop” then that is the psyop. When someone says: “these drag queens are groomers” they are the groomers. When someone says: “the establishment wants to keep you stupid and poor” they are the establishment who want to keep you stupid and poor.
It’s so important to realize that most of “the establishment” are the pawns who are just as guilty. Thank you.
Also “The establishment” when used in accusations can be replaced by “Rich bastards and right-wingers” and the accusations are usually spot on. Child abuse, sexual assault, market manipulation, bribery, always checks out perfectly.
That’s where I feel our perspectives diverge. I think there is a sickness that is rooted within the heart of the human experience and it is a fear-based compulsion based on power/control. Some (the rich) have means to express this sickness in larger domains, but it is a characteristic that seems to be independent of wealth. I think there are people with this illness, and those without, and those somewhere on a curve.
We have been at this stage at least since the cold war my friend. Every accusation is an admission. They cannot allow the people at large to imagine a world without the evils incentivised by capitalism.
AI is either a solution in search of a problem,
or it’s the next scheme designed to gobble up as much VC money as possible and boost NVIDIA stock value, now that the Cryptocurrency bubble has passed.
I wasn’t under the impression American AI was profitable either. I thought it was held up by VC funding and over valued stock. I may be wrong though. Haven’t done a deep dive on it.
Okay, I literally didn’t even post the comment yet and did the most shallow of dives. Open AI is not profitable. https://www.cnbc.com/2024/09/27/openai-sees-5-billion-loss-this-year-on-3point7-billion-in-revenue.html
The CEO said on twitter that even their $200/month pro plan was losing money on every customer: https://techcrunch.com/2025/01/05/openai-is-losing-money-on-its-pricey-chatgpt-pro-plan-ceo-sam-altman-says/
I don’t see how they would become profitable any time soon if their costs are that high. Maybe if they adapt the innovations of deepseek to their own model.
Haven’t done a deep dive on it.
deep seek you mean?
👉😎👉
To the rich being overvalued and being profitable are indistinguishable.
I get your point, but I mean the business being profitable from an accounting perspective, not the stock being profitable from an investing perspective.
















{kind=link}